En esta guía descubrirás 10 ejemplos de bases de datos relacionales reales, un estudio de caso y un checklist que te ayudará a aplicar buenas prácticas desde hoy.
Las bases de datos relacionales siguen siendo el pilar de millones de aplicaciones en 2025. Su fortaleza radica en la integridad de los datos, la flexibilidad del lenguaje SQL y la posibilidad de escalar horizontalmente con tecnologías modernas como PostgreSQL XL o Vitess.
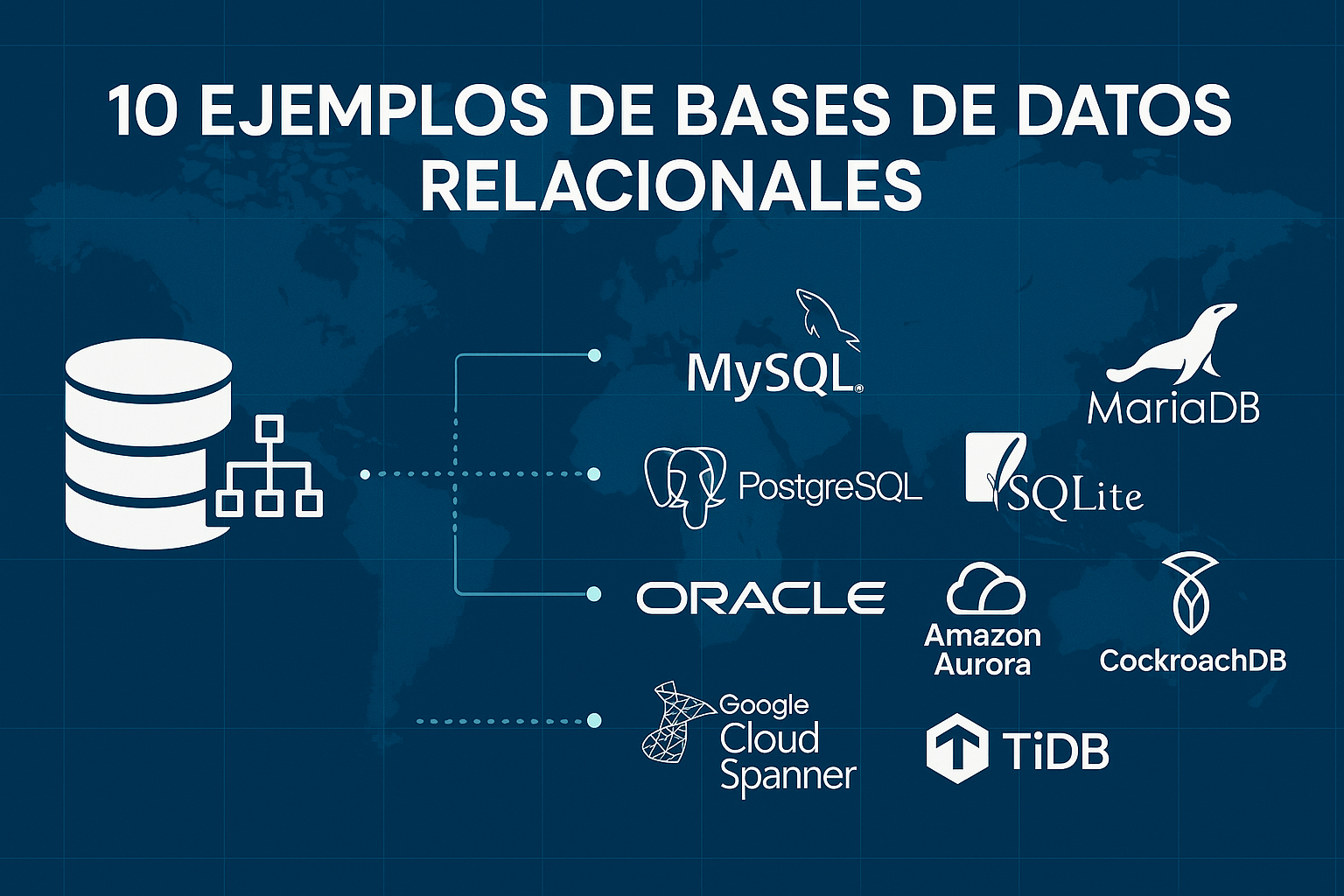
¿Qué es una base de datos relacional?
Una base de datos relacional es un conjunto de tablas relacionadas mediante claves primarias y foráneas que modelan entidades del mundo real. Este paradigma, propuesto por Edgar F. Codd, asegura consistencia y permite consultas complejas con Álgebra Relacional.
Tipos de relaciones en bases de datos
- 1 : 1 — Un empleado ↔️ un número de seguridad social.
- 1 : N — Un cliente ↔️ muchas órdenes.
- N : M — Muchos estudiantes ↔️ muchos cursos (tabla puente “matrículas”).
Criterios para elegir un buen ejemplo relacional
| Criterio | Por qué importa |
|---|---|
| Escalabilidad | Facilita particiones (sharding) y replicación. |
| Integridad referencial | Garantiza datos coherentes sin redundancia. |
| Soporte comunitario | Documentación abundante y parches de seguridad frecuentes. |
| Compatibilidad con ORMs | Reduce la fricción en desarrollo con frameworks modernos. |
10 ejemplos de bases de datos relacionales
MySQL
Caso de uso principal: CMS como WordPress y tiendas e-commerce de tamaño medio, así como micro-SaaS que requieren una base de datos relacional fácil de alojar y escalar.
| Aspecto | Detalle |
|---|---|
| Licencia | Community Edition (GPL) + Enterprise Edition (propietaria) |
| Modelo de lanzamiento 2025 | LTS (8.4.x) para estabilidad a 8 años e Innovation (9.x) con novedades trimestrales blogs.oracle.com |
| Almacenamiento por defecto | InnoDB (ACID, MVCC, índices B-tree, FTS, JSON) |
| Alta disponibilidad | Replica asíncrona, Group Replication, InnoDB ClusterSet, NDB Cluster |
| Últimas novedades 9.x | Tipo VECTOR para IA, programas almacenados en JavaScript, restricciones FK implícitas bytebase.comdbngin.com |
Ventajas clave
- Ecosistema masivo de extensiones, plugins y ORMs; prácticamente todos los proveedores de hosting lo ofrecen con instalación en un clic (cPanel, Plesk, etc.).
- Curva de aprendizaje corta: abundante documentación, cursos y una comunidad activa de millones de desarrolladores.
- Flexibilidad de despliegue: contenedores Docker oficiales, imágenes optimizadas para Kubernetes y servicios gestionados (Amazon RDS/Aurora, Google Cloud SQL, Oracle HeatWave).
- Costes bajos de operación: la edición Community cubre el 90 % de los casos sin licencias de pago dev.mysql.com.
Desventajas o limitaciones
- Funcionalidades exclusivas de Enterprise (p. ej. MySQL Firewall, Thread Pooling, Backup Encryptado y HeatWave para analytics in-memory) exigen licenciamiento adicional mysql.com.
- Replicación asíncrona tradicional puede provocar lag en picos de escritura; se recomienda Group Replication o Aurora MySQL para minimizarlo.
- Solo se permite un trigger BEFORE y AFTER por tabla y evento, lo que complica ciertas validaciones complejas.
Arquitectura típica para WordPress & e-commerce
textCopiarEditar[Clientes Web] → Nginx/Apache → PHP-FPM ──► MySQL Primary
└─► Read Replica (Consultas SELECT)
- Primary maneja escrituras; réplicas escalan lectura y generan informes.
- Utiliza InnoDB Buffer Pool ≥ 70 % de RAM para acelerar lecturas.
- Activa Binary Logs + GTID para restauraciones punto-en-el-tiempo.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
innodb_flush_log_at_trx_commit=2 en cargas moderadas | Reduce I/O de disco sin sacrificar durabilidad. |
Índices compuestos basados en consultas (p. ej. (post_type, post_date)) | Mejora listados con paginación en WordPress. |
slow_query_log + pt-query-digest | Identifica cuellos de botella antes de escalar hardware. |
| Comprimir backups con mysqlpump –parallel | Disminuye tiempo de copia hasta 3× frente a mysqldump. |
Ejemplo de modelo relacional (Blog)
| Tabla | Clave primaria | Relaciones |
|---|---|---|
wp_users | ID | 1 :N con wp_posts |
wp_posts | ID | 1 :N con wp_comments |
wp_comments | comment_ID | N :1 con wp_posts |
Este ejemplo de base de datos relacional ilustra la relación 1:N que sustenta la lógica de cualquier CMS, y sirve como patrón para diseñar catálogos de productos en e-commerce.
Checklist rápido para tu instancia MySQL
- Versionar tu esquema con migrations (p. ej. Flyway).
- Forzar
utf8mb4como charset por defecto. - Habilitar AUTOMATIC BACKUP diario + verificación de integridad.
- Revisar el plan de consultas con
EXPLAIN ANALYZE. - Activar Group Replication si tu SLA exige < 5 s RTO.
MySQL sigue siendo un ejemplo de base de datos relacional imbatible por su equilibrio entre costo, rendimiento y ecosistema. Para proyectos de contenido dinámico y catálogos de productos —como WordPress o WooCommerce— ofrece la mejor relación rapidez-precio, siempre que complementes la Community Edition con buenas prácticas de seguridad y monitoreo.
PostgreSQL
Caso de uso principal: plataformas fintech (core bancario, pagos en tiempo real) y analítica geoespacial con la extensión PostGIS.
| Aspecto | Detalle |
|---|---|
| Licencia | 100 % open-source (PostgreSQL 17) + distribuciones comerciales (EDB, Crunchy, Neon) |
| Última versión estable (2025) | PostgreSQL 17 – mejoras de rendimiento VACUUM 20×, JSON TABLE y optimizaciones I/O de hasta 2× postgresql.org |
| Geoespacial | PostGIS 3.5 – compatible PG 12-17; nuevas funciones ST_* y mejor rendimiento ST_GeneratePoints postgis.net |
| Tipos de datos avanzados | JSONB, VECTOR (pgvector), range types (tsrange, numrange, etc.) |
| Alta disponibilidad | Replicación lógica/streaming, Patroni, pg_auto_failover; soporta zero-downtime upgrades desde PG 17 postgresql.org |
| Escalado cloud | Amazon Aurora Postgres, Google Cloud Spanner (compat), Azure Flexible Server; Kubernetes con Crunchy PGO |
Ventajas clave
- JSONB → almacena y consulta datos semiestructurados con índices GIN; ideal para trazabilidad de transacciones y payloads PSD2 speakdatascience.com.
- Range types (
tsrange,numrange) simplifican ventanas de tiempo y límites de crédito sin tablas auxiliares postgresql.org. - Extensibilidad geoespacial: PostGIS añade +300 funciones GIS, soporte raster y topology; indispensable para scoring de riesgo basado en ubicación postgis.net.
- Confiabilidad “finance-grade”: instituciones como Goldman Sachs, Revolut y Morgan Stanley usan Postgres en producción, demostrando cumplimiento regulatorio y capacidad de escalar a millones de usuarios enterprisedb.com.
Desventaja o barrera
- Curva de aprendizaje ligeramente mayor que MySQL debido a la amplitud del ecosistema (tipos avanzados, extensiones, planificador más rico). Se mitiga con guías oficiales y managed services.
Arquitectura típica en FinTech (pagos en tiempo real)
textCopiarEditar┌──────────────────────┐ Logical Replication ┌─────────────────────┐
│ Primary (PG 17) │ ─────────────────────────────────► │ Hot Standby (RO) │
│ • WAL archiving │ │ Read Scaling │
│ • pgBouncer pool │ └─────────────────────┘
│ • pgvector + JSONB │
└─────────▲────────────┘
│ Streaming Replication
┌─────────┴────────────┐
│ Patroni / etcd │—→ automatic fail-over (<5 s RTO)
└──────────────────────┘
- Segmenta cuentas por particiones hash (
PARTITION BY HASH(account_id)) y agrupa movimientos diarios en table inheritance para archivado. - Exponer API de pagos con READ COMMITTED + advisory locks para evitar carreras de saldo.
- Para geocercas antifraude, usar
ST_DWithin(tx_location, region, 50)con índice GIST.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
shared_buffers ≈ 25 % RAM + work_mem dinámico | Evita spill a disco en cálculos de agregados. |
Índices GIN en JSONB (jsonb_path_ops) | Aceleran búsquedas de campos anidados 5-10×. |
pgvector + HNSW (lists=500) | Similarity search < 10 ms con 1 M vectores crunchydata.com |
Estrategia multicolumna ((merchant_id, tx_time)) | Filtra rangos de fechas en reporting sin bitmap heap. |
Ejemplo de esquema (pagos y geolocalización)
| Tabla | PK | Relaciones | Tipo destacable |
|---|---|---|---|
accounts | id | 1 :N con transactions | NUMRANGE(balance_range) |
transactions | tx_id | N :1 con accounts | JSONB (metadata), POINT (tx_location) |
geofences | gid | N :M con accounts vía account_zone | POLYGON (PostGIS) |
Checklist rápido para tu clúster PostgreSQL
- Activar logical replication slots permanentes para ETL sin impacto en primario.
- Configurar
max_slot_wal_keep_size = 5GBpara evitar overflow en picos de escritura. - Usar
CREATE INDEX ON transactions USING GIST (tx_location)para consultas de proximidad. - Adoptar incremental backups con
pg_basebackup --incremental-mode=delta. - Verificar alertas en pg_stat_activity y nuevo
pg_wait_events(PG 17). - Mantener PostGIS y extensiones en la misma versión menor del servidor.
- Documentar objetos con
COMMENT ONpara E-E-A-T y gobernanza de datos.
Gracias a su combinación de consistencia ACID, extensiones como PostGIS y tipos de datos como JSONB y rangos, PostgreSQL 17 se posiciona como la base ideal para soluciones fintech que necesitan seguridad regulatoria y, al mismo tiempo, flexibilidad para analíticas geoespaciales avanzadas. Con una adopción probada en bancos globales y startups por igual, representa un ejemplo de base de datos relacional preparado para el futuro.
MariaDB
Fork 100 % comunitario de MySQL que aporta el motor Aria y réplicas más rápidas gracias a nuevas optimizaciones en la serie 11.x.
| Aspecto | Detalle |
|---|---|
| Licencia | GPL v2 (Community Server) + Enterprise Server opcional |
| Versión LTS (2025) | MariaDB 11.4 (GA desde feb 2025, soporte hasta 2029) mariadb.com |
| Motor destacado | Aria: crash-safe, footprint ligero, caché mejor que MyISAM; todas las tablas del sistema usan Aria desde 10.4 mariadb.com |
| Mejoras de replicación | Índice GTID en binary logs y límite global de espacio (max_binlog_total_size) que reducen el lag en réplicas grandes (11.3 +) mariadb.com |
| Alta disponibilidad | Galera Cluster 4, standard replication, MaxScale como proxy/sql-firewall |
| Escalado cloud | SkySQL, Kubernetes Operator, servicios gestionados en AWS/GCP/Azure |
Ventajas clave
- Aria acelera GROUP BY y DISTINCT con mejor caché y permite copiar ficheros fácilmente entre servidores. mariadb.com
- Réplica más eficiente: el índice GTID evita escaneos completos del binlog y el nuevo límite de tamaño purga automáticamente ficheros viejos sin perder coherencia. mariadb.com
- Compatibilidad drop-in con MySQL 8.x: migraciones mínimas y soporte para la mayoría de los ORMs.
- Comunidad muy activa y parches rápidos; roadmap público y bug tracker abierto.
Desventajas o limitaciones
- Curva de aprendizaje mayor frente a MySQL: más motores (Aria, MyRocks, ColumnStore), parámetros extra y divergencias sintácticas menores.
- Algunas funciones empresariales (backup en caliente, Firewall SQL ampliado) solo en Enterprise Server.
Arquitectura típica (lecturas globales + escrituras locales)
textCopiarEditar┌─────────────┐ Async Replication ┌─────────────┐
│ Primario │◄──────────────────────│ Réplica EU │
│ US-East │──GTID Index──────────►│ Read-Only │
└─────▲───────┘ └─────────────┘
│ |
│ └─► Réplica AP-Southeast (Read-Only)
│
MaxScale (RW-Split, Firewall)
- Variable
max_binlog_total_size=50Gmantiene controlado el disco. - GTID-based fail-over gestionado por MariaDB Monitor en MaxScale.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
innodb_flush_log_at_trx_commit=2 + sync_binlog=1 | Balancea durabilidad/costes E/S. |
Activar binlog_gtid_index=ON (default) | Réplicas encuentran posición 5-10 × más rápido. |
Aria para tablas temporales grandes (ENGINE=Aria ROW_FORMAT=PAGE) | Reduce uso de tmpdir. |
maxscale.modules=readconnroute, binlogrouter | Escala lecturas y simplifica réplica multi-región. |
Ejemplo de esquema (Marketplace)
| Tabla | PK | Motor | Relaciones |
|---|---|---|---|
users | id | InnoDB | 1 :N orders |
products | id | InnoDB | 1 :N order_items |
orders | id | Aria | N :1 users |
order_items | (order_id, product_id) | Aria | N :1 orders, N :1 products |
Por qué Aria en
ordersyorder_items: consultas de lectura masiva con JOIN benefician el page cache de Aria, manteniendo transacciones críticas en InnoDB.
Checklist rápido para tu clúster MariaDB
- Fijar
max_binlog_total_sizeyexpire_logs_dayspara controlar disco. - Usar
SET GLOBAL gtid_slave_posen fail-over para arranque instantáneo. - Migrar tablas del sistema a Aria (
mysql_upgrade) si vienes de < 10.4. - Habilitar MariaDB Backup incremental (
mariabackup --incremental). - Monitorizar el lag con
SHOW ALL SLAVES STATUS\G. - Documentar motores y claves foráneas con
COMMENT ON TABLE.
MariaDB 11.4 ofrece un equilibrio único entre innovación comunitaria y rendimiento real en producción: el motor Aria reduce costes de almacenamiento y las nuevas optimizaciones de replicación mejoran la escalabilidad global. Si buscas un drop-in de MySQL con mayor libertad y prestaciones modernas, MariaDB es tu próximo ejemplo de base de datos relacional preparado para 2025.
SQLite
Caso de uso principal: apps móviles (Android/iOS) y dispositivos IoT que requieren almacenamiento local ligero y sin servidor.
| Aspecto | Detalle |
|---|---|
| Licencia | Dominio público (SQLite Public Domain) |
| Versión estable (2025) | SQLite 3.45 – añade JSONB on-disk, optimizaciones de CPU ≈22 % y mejoras en consultas de grandes star joins antonz.org |
| Formato de archivo | Único archivo .db; configuración = 0 (“servo-zero”) sqlite.org |
| Modo journal recomendado | WAL (Write-Ahead Logging) para lecturas concurrentes y checkpoint automático sqlite.org |
| Concurrencia | Muchos lectores / un escritor; las escrituras en paralelo quedan en cola → adecuada para cargas ligeras (IoT) pero no para OLTP pesado stackoverflow.com |
Ventajas clave
- Footprint mínimo (< 1 MB) y cero dependencias, ideal para dispositivos con RAM/flash limitadas.
- Portabilidad total: la base se mueve como un archivo común; facilita backups instantáneos y sincronización diferida.
- JSONB & FTS5: desde 3.45 almacena árboles JSON pre-parseados y soporta búsquedas full-text nativas, útiles para payloads de APIs y registros locales.
- Cross-plataforma: compatible con C/C++, Java/Kotlin (Android), Swift (iOS) y micropython; la misma base corre en edge devices y backend. geekboots.com
Desventajas o limitaciones
- Baja concurrencia de escritura: incluso con WAL, solo un hilo/cliente puede escribir a la vez; los demás quedan bloqueados ➜ no apropiado para tráfico transaccional masivo. stackoverflow.com
- Sin gestión de usuarios/roles; la seguridad depende del contenedor o cifrado externo (SQLCipher).
- Reinventar alta disponibilidad: requiere capas adicionales (sincronización/replicación) si se necesita fail-over.
Arquitectura típica en móvil/IoT
textCopiarEditar┌────────────┐ Local writes (WAL) ┌────────────┐
│ App/Edge │ ───────────────────────► │ SQLite DB │
│ (Swift/K) │ ◄── SELECT / cache ───── │ *.db file │
└─────▲──────┘ └────┬───────┘
│ Batch sync (MQTT/REST) │ Snapshot
▼ ▼
┌────────────────┐ ┌────────────┐
│ Cloud API │ ←──────────────┐ │ S3/GCS │
└────────────────┘ Backups
- El dispositivo escribe en WAL, que permite lectura paralela de la UI.
- Un worker de fondo envía deltas JSON a la nube cuando hay conectividad.
- Backups = copia del archivo .db o
VACUUM INTO.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
PRAGMA journal_mode=WAL; | Separar escrituras → lecturas sin bloquear. |
PRAGMA synchronous=NORMAL; en móviles | Reduce fsync costoso; mantiene durabilidad aceptable. |
PRAGMA page_size=4096; | Alinea con bloques flash para menos desgaste. |
Transacciones cortas & BATCH INSERT | Evita bloqueos largos durante escritura. |
Índice compuesto en (device_id, timestamp) | Acelera lectura temporal de sensores. |
Ejemplo de esquema (Sensores IoT)
| Tabla | PK | Campos clave | Comentario |
|---|---|---|---|
sensors | id | name TEXT, location TEXT | Lista de dispositivos |
readings | (sensor_id, ts) | value REAL, payload JSONB | 1 :N con sensors; payload guarda datos crudos |
Por qué JSONB en
readings: almacena payloads heterogéneos (distintas métricas) sin alterar el esquema y admite búsquedas indexadas por clave.
Checklist rápido para tu base SQLite
- Activar WAL y programar
PRAGMA wal_checkpoint(TRUNCATE);diario. - Comprimir backups con
zstd; tamaño típico < 50 MB para 1 M filas. - Cifrar el archivo con SQLCipher si contiene datos sensibles.
- Limitar tamaño de base (
PRAGMA max_page_count) en dispositivos con flash pequeña. - Automatizar pruebas de integridad con
PRAGMA quick_check;al iniciar la app. - Migrar al nuevo JSONB si tu carga usa datos semiestructurados.
SQLite 3.45 sigue siendo el ejemplo de base de datos relacional embebida por excelencia: archivo único, cero configuración y un núcleo ACID robusto. Si tu proyecto se centra en apps móviles o IoT edge, obtendrás rapidez de arranque y simplicidad inigualables. Solo recuerda diseñar un buffer de escritura o sincronización asincrónica cuando tu carga pueda generar picos de escrituras concurrentes.
Oracle Database
Caso de uso principal: cargas corporativas “tier-1” (core banking, BSS/OSS telco, ERP, billing) que exigen máxima disponibilidad y rendimiento lineal mediante RAC + Partitioning.
| Aspecto | Detalle |
|---|---|
| Licencia | Enterprise Edition (EE) — ≈ USD 47 500 / CPU + 22 % anual de soporte; opciones como RAC y Partitioning se licencian aparte oraclelicensingexperts.comatonementlicensing.com |
| Última versión estable | Oracle Database 23 ai (23c) — GA, soporte Premier 5 años; añade AI Vector Search, True Cache y JavaScript SPs blogs.oracle.comsupport.oracle.com |
| Alta disponibilidad | RAC (escala-todo con fail-over < 5 s), Data Guard, Two-Stage Rolling Updates para “zero-downtime” patching dbops-tech.comdocs.oracle.com |
| Partitioning 23ai | Interval- & auto-list híbrido, bulk drop rápido, metadatos enriquecidos oracle-base.comoracle-base.com |
| Escalado cloud | Exadata X-series on-prem / Oracle Cloud (OCI) + Autonomous Database; RAC sobre OCI para HA global oracle.comlearnomate.org |
Ventajas clave
- RAC = 99,99 % uptime: varias instancias acceden al mismo almacenamiento; bancos y telcos confían en él para procesar miles de TPS sin parada oracle.comlearnomate.org.
- Partitioning avanzado: híbrido interno/externo, interval-hash-sub combinables; ideal para facturación masiva y historificación regulatoria oracle-base.com.
- Converged DB: en la misma instancia conviven SQL, JSON Relational Duality, vectores, blockchain y gráficos, reduciendo ETL y latencia oracle.com.
- Patching inteligente: Two-Stage Rolling Updates arranca un segundo proceso en el mismo nodo y mueve sesiones sin corte (23ai) dbops-tech.com.
Desventajas o barreras
- Licenciamiento elevado y complejo (CPU + opciones + soporte), especialmente al habilitar RAC y Partitioning; coste total puede superar seis cifras en proyectos medianos oraclelicensingexperts.comatonementlicensing.com.
- Fuerte especialización DBA: administrar CRS, ASM, patch-bundles y tuning multi-nodo requiere perfiles senior y formación certificada.
Arquitectura típica Banco/Telco (OLTP crítico + analítica)
textCopiarEditarClients ↔ Load Balancer ─────────┐
│
┌─────────────▶ RAC Node 1 (RW)
│ + Partitioned Tables
│
├─────────────▶ RAC Node 2 (RW)
│
App Tier ───┤
│ Streaming Replication / ADG
│
└─────────────▶ Stand-by (Reporting, DR)
│
Vector Search / JSON API
- RAC distribuye lecturas y escrituras entre nodos; ASM gestiona el almacenamiento compartido.
- Partitioning list-range sobre tablas
TRANSACTIONSyCALL_DETAILmejora purgado y pruning. - Activa AI Vector Search (23ai) para scoring antifraude en tiempo real oracle.comdocs.oracle.com.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
PARALLEL_DEGREE_POLICY = AUTO | Ajusta workers según carga sin sobrecargar CPU. |
PARTITIONED TABLE + LOCAL INDEX | Pruning en consultas mensuales; reduce I/O 10-20×. |
| Services + Instance-preferred | Balancea workloads OLTP / analytics dentro del RAC. |
DBMS_RESOURCE_MANAGER | Prioriza transacciones frente a batch; evita log file sync alto. |
Ejemplo de esquema (Core Banking)
| Tabla | PK | Partición | Comentario |
|---|---|---|---|
ACCOUNTS | acct_id | HASH (600 buckets) | Distribuye I/O en cluster |
TXN_LEDGER | txn_id | RANGE (month) + SUBPART HASH(acct_id) | Purga mensual automatizada |
CALL_DETAIL | cdr_id | INTERVAL LIST(region) | Telco BSS; unifica archivo externo |
Checklist rápido Oracle 23ai
- Diseñar RAC mínimo 2 nodos + ASM; verificar interconnect > 25 Gbps.
- Licenciar Partitioning y probar interval + hybrid antes de producción.
- Configurar Two-Stage Rolling Updates para parches trimestrales.
- Habilitar AI Vector Search y JSON Duality solo en tablas clave para ahorrar CPU.
- Revisar uso de opciones con
dba_feature_usage_statisticspara evitar costos ocultos. - Planificar segregación de tenants con PDBs; un PDB ↔ un negocio/línea de servicio.
Oracle Database 23ai continúa siendo el estándar de oro en entornos bancarios y telco donde la tolerancia a fallos y el rendimiento lineal son innegociables. Su combinación de RAC, Partitioning y un conjunto convergente de motores permite consolidar OLTP, analítica y workloads de IA en una sola plataforma. El precio es elevado, pero el ROI se justifica cuando el coste de un minuto de inactividad supera con creces la inversión en licencias y especialistas.
Microsoft SQL Server
Caso de uso principal: aplicaciones .NET de misión crítica y BI corporativo con SSIS (ETL), SSAS (cubos Tabular/MOLAP) y SSRS (reporting).
| Aspecto | Detalle |
|---|---|
| Licencia | Enterprise/Standard/Express/Developer; Enterprise ≈ USD 7 000 por núcleo + ~23 % Software Assurance (2025) redmondmag.com |
| Modelos de licenciamiento | Per Core (mín. 4 núcleos) y Server + CAL; Core permite acceso ilimitado de usuarios remend.com |
| Versión estable (2025) | SQL Server 2025 (17.x Preview): Intelligent Query Processing v4, AI Vector Search y eliminación de Data Quality Services learn.microsoft.com |
| .NET nativo | Nuevo Microsoft.Data.SqlClient con autenticación Entra en ADO.NET/EF Core; soporte oficial para .NET 8 techcommunity.microsoft.com |
| SSIS 2025 | Driver SqlClient en Connection Manager, mejoras en Scale-Out y deprecación de servicios legados learn.microsoft.comtechcommunity.microsoft.com |
| SSAS 2025 | Biblioteca SqlClient actualizada, eliminación de PowerPivot para SharePoint powerbi.microsoft.com |
| Cloud & híbrido | Azure SQL MI, SQL on AKS, y Synapse Link para analítica cuasi-tiempo-real learn.microsoft.com |
Ventajas clave
- Integración .NET “first-class”: ORM Entity Framework Core, LINQ y tooling Visual Studio brindan productividad instantánea.
- Pila BI unificada: SSIS (orquestación ETL), SSAS (modelado semántico) y SSRS (render multi-formato) — todo administrado desde SQL Server Management Studio.
- Intelligent Query Processing v4 mejora rendimiento sin refactorizar código (DOP feedback, cardinality estimator adaptativo).
- AI Vector Search en 2025 permite búsquedas de similitud y RAG sobre embeddings dentro del motor.
Desventajas o barreras
- Coste elevado de licencias Enterprise y opciones SA; requiere análisis TCO frente a alternativas open-source redmondmag.com.
- Dependencia Windows en features legacy (DTC, SSRS nativo); aunque Linux es soportado, ciertas extensiones siguen exclusivas de Windows.
Arquitectura típica (.NET + BI)
textCopiarEditar[ASP.NET 8 API] ──► SqlClient ► SQL Server 2025
│
┌──────────┴───────────┐
│ │ │
SSIS Scale-Out SSAS Tabular SSRS Portal
(ETL pipelines) (datos cube) (paginated)
- SSIS Scale-Out procesa datos y los publica en staging.
- SSAS expone modelos a Power BI / Excel vía XMLA o DAX.
- Synapse Link replica cambios para analítica serverless.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
Table Partitioning (HASH/INTERVAL) + ONLINE=ON | Mantenimiento sin ventana de corte, ideal para facturación. |
| Habilitar Memory Grant Feedback & Parameter Sensitive Plan | Reduce “spill” y plan skew en cargas variables. |
COLUMNSTORE en tablas históricas | Compresión 10-20×, acelera Power BI. |
ADF + SSIS IR en Azure | Escala ETL sin gestionar VMs; paga-por-uso. |
Ejemplo de esquema (Retail BI Star)
| Tabla | Tipo | Comentario |
|---|---|---|
FactSales | COLUMNSTORE, RANGE (fecha) | Métricas monetarias; FK a dimensiones |
DimDate | HEAP | Calendario empresarial |
DimProduct | IN-MEMORY OLTP | Alta consulta web |
DimStore | HASH INDEX | Geolocalización tiendas |
SSIS extrae del ERP, Partition Switch ingiere a
FactSales, y SSAS Tabular consume el esquema para dashboards.
Checklist rápido SQL Server 2025
- Evaluar Core vs Server + CAL según Nº de usuarios.
- Migrar drivers a Microsoft.Data.SqlClient para Entra auth.
- Activar Query Store (modo read-write) antes de producción.
- Planificar degradación controlada de DQS si existía en 2022.
- Configurar Always On Availability Groups con réplicas de solo lectura.
- Implementar Synapse Link si BI exige < 5 min de latencia.
Microsoft SQL Server 2025 sigue siendo la opción predilecta cuando necesitas integración profunda con .NET y una suite BI completa (SSIS/SSAS/SSRS) en la misma licencia. La llegada de Vector Search y mejoras en Intelligent Query Processing refuerzan su competitividad frente a motores open-source, mientras que el coste premium se justifica en organizaciones que valoran un ecosistema totalmente unificado y soportado por Microsoft.
Amazon Aurora (MySQL / PostgreSQL)
Caso de uso principal: SaaS globales y cargas variablemente intensivas (fintech, gaming, marketplaces) que exigen autoscaling al segundo y continuidad operativa multi-región.
| Aspecto | Detalle |
|---|---|
| Servicio | 100 % gestionado en AWS (PaaS); licenciamiento pay-as-you-go – CPU/ACU, storage y I/O |
| Compatibilidad | MySQL 8.0 (Aurora MySQL 3.09, mayo 2025) docs.aws.amazon.com |
| Autoscaling | Aurora Serverless v2: añade/retira 0.5 ACU en segundos, facturación por segundo docs.aws.amazon.com |
| Alta disponibilidad | Multi-AZ con fail-over ≤ 30 s; hasta 15 réplicas de lectura por clúster aws.amazon.com |
| Multi-región | Global Database: latencia de réplica < 1 s entre regiones docs.aws.amazon.com |
| Optimización costosa de I/O | Aurora I/O-Optimized ahorra hasta 40 % en cargas intensivas aws.amazon.com |
| Analítica | Zero-ETL → Redshift (GA oct 2024) para analítica casi tiempo-real aws.amazon.com |
Ventajas clave
- Escalado granular (0.5 ACU) evita sobre-aprovisionar y responde a picos imprevisibles. docs.aws.amazon.com
- Tolerancia regional con Global DB: RPO ≈ 0 s, RTO < 1 min; ideal para normativas bancarias. docs.aws.amazon.com
- I/O-Optimized mejora throughput y ofrece costes predecibles para workloads > 25 % I/O spend. aws.amazon.com
- Zero-ETL elimina pipelines y replica cambios a Redshift en segundos para ML y dashboards. aws.amazon.com
Desventajas o limitaciones
- Vendor lock-in: APIs y facturación ligadas a AWS; migrar fuera requiere dump y reload.
- Sobre-coste de almacenamiento frente a RDS estándar en cargas ligeras I/O.
- Algunas extensiones nativas de MySQL/PostgreSQL (e.g., MyISAM,
pglogical) no están soportadas o requieren versiones específicas.
Arquitectura típica (Aurora Serverless v2 + Global DB)
textCopiarEditar┌────────────┐ Multi-AZ ┌────────────┐
│ Writer │◄───── Replicas ────────►│ Reader R1 │ ... up to 15
│ (ACU 4-64) │ └────────────┘
└────┬────────┘
│ Global <1 s
┌────▼────────┐
│ Secondary │ (EU-West-1, ACU 1-16)
│ Region │ • Read-only / DR
└─────────────┘
▲ Zero-ETL (DDL+DML)
│
Amazon Redshift (analytics/ML)
- Serverless v2 ajusta ACU por minuto; Global DB asíncrona usa replicación a nivel de storage.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
| I/O-Optimized en workloads > 25 % I/O | Hasta 40 % ahorro coste / menor latencia aws.amazon.com |
| Mín./Máx. ACU ajustados a demanda real | Evita throttling y ahorra en inactividad. |
| Réplicas distribuidas en zonas y regiones | Absorben lecturas y reducen latencia global. |
| Performance Insights + Query Plan Management | Identifica SQL lentas y bloquea planes óptimos. |
| Activar backtrack (MySQL) o pitr (PG) | Recuperación puntual sin restaurar backups completos. |
Ejemplo de esquema (Marketplace SaaS)
| Tabla | PK | Partición | Comentario |
|---|---|---|---|
tenants | tenant_id | HASH | Serverless v2 multitenant |
orders | order_id | RANGE (month) | Replica en Global DB para BI |
order_items | (order_id, item_id) | N/A | Foreign-key a orders |
Checklist rápido para tu clúster Aurora
- Elegir MySQL 3.09 o PostgreSQL 16.4 según tu stack.
- Definir rangos ACU prudentes (
min=0.5,max=64). - Activar Global DB si SLA exige < 1 min RTO cross-región.
- Evaluar I/O-Optimized si I/O $ > 25 % del gasto total.
- Configurar zero-ETL a Redshift para reporting sub-minuto.
- Habilitar rendimiento con
aurora_parallel_query(MySQL) ords.force_autovacuum_logging_level. - Pruebas trimestrales de fail-over y escalado ACU.
Amazon Aurora combina la familiaridad de MySQL/PostgreSQL con la capacidad de autoscalar al segundo, replicar con < 1 s de latencia entre regiones y enviar datos a Redshift sin ETL. Su modelo gestionado y las nuevas opciones Serverless v2 e I/O-Optimized lo convierten en el ejemplo de base de datos relacional cloud-native para 2025, siempre que estés cómodo con la dependencia de AWS y ajustes los rangos ACU a tu patrón de tráfico.
Google Cloud Spanner
Caso de uso principal: SaaS globales con millones de usuarios simultáneos que necesitan SQL, consistencia fuerte y escalado horizontal ilimitado sin sacrificar disponibilidad.
| Aspecto | Detalle |
|---|---|
| Servicio | Totalmente gestionado en Google Cloud; tarifas pay-as-you-go (nodos/uCPUs, almacenamiento, I/O). |
| Ediciones (2024-25) | Standard, Enterprise y Enterprise Plus—la última amplía acceso a gráficos, búsqueda full-text y vector search en la misma instancia cloud.google.com. |
| Compatibilidad SQL | Dialectos GoogleSQL y PostgreSQL (interface GA, gestión unificada) cloud.google.comcloud.google.com |
| Analítica serverless | Spanner Data Boost: computación independiente para consultas y exportaciones analíticas sin impacto OLTP cloud.google.comtechcrunch.com |
| Novedades 2025 | Tiered Storage GA (SSD + HDD) y External BigQuery dataset link GA, eliminando ETL cloud.google.com |
| Alta disponibilidad | 99.999 % SLA en multirregión; replicas automáticas sincronizadas con TrueTime. |
Ventajas clave
- Consistencia global fuerte con latencias de lectura/escritura predictibles gracias a TrueTime.
- Escalado lineal: añadir nodos eleva QPS sin particionar manualmente; ideal para picos imprevisibles en SaaS.
- Multi-modelo convergente (relacional + vector + graph + FTS) en Enterprise/Plus, eliminando silos de datos cloud.google.com.
- Data Boost permite ejecutar Spark, Dataflow o BigQuery sobre la misma base sin afectar transacciones cloud.google.comtechcrunch.com.
- PostgreSQL interface reduce fricción de migración y habilita herramientas estándar PG cloud.google.com.
Desventajas o limitaciones
- Precio inicial elevado (mín. 1 nodo/region) y facturación en múltiples dimensiones; no rentable para cargas pequeñas.
- Dependencia exclusiva de Google Cloud (vendor lock-in).
- Aún faltan algunas extensiones nativas de PostgreSQL (p. ej.
pgcrypto) y no hay soporte para triggers complejos.
Arquitectura típica SaaS multirregión
textCopiarEditar┌────────────┐ gRPC/HTTP ┌────────────┐
│ App US │────────────────────►│ Spanner │
│ (Cloud Run) │◄────────────────────│ Primary │
└─────▲───────┘ └─────┬───────┘
│ External table link │
│ ▼ <1 s replication
┌─────┴───────┐ ┌────────────┐
│ BigQuery │ ◄── Zero-ETL ───── │ Secondary │
│ Analytics │ │ (EU-West) │
└─────────────┘ └────────────┘
▲ │
│ Data Boost (serverless) │
└──────────┬────────────────────┘
▼
Dataflow / Spark
- Data Boost lanza computación analítica on-demand; External BigQuery dataset consulta el mismo almacenamiento sin mover datos.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
| Choose Edition sabiamente: Enterprise Plus solo si necesitas vectors/graph; reduce sobrecoste. | |
| Regional + Read-only replicas para workloads mayormente lectura; ahorra hasta 30 %. | |
| Multi-région con 3+ réplicas si tu SLA requiere RPO ≈ 0 s y RTO < 60 s. | |
Partition tables por clave de usuario (CREATE TABLE … PARTITION BY HASH(user_id)) para distribución uniforme. | |
| Activa Data Boost en queries > 30 s o exportaciones masivas—evita impacto en OLTP. | |
Limita columnas de tipo STRING(MAX); usa Tiered Storage para históricos masivos cloud.google.com. |
Ejemplo de esquema (Plataforma de mensajería global)
| Tabla | PK | Partición | Comentario |
|---|---|---|---|
users | user_id | HASH | Perfil y preferencias |
conversations | conv_id | HASH | Metadatos de sala |
messages | (conv_id, ts) | RANGE (día) | Millones/día; usa Data Boost para analytics |
vector_index | msg_id | N/A | Vectores embedding (Enterprise Plus) |
Checklist rápido para tu instancia Spanner
- Seleccionar edición (Standard/Ent/Ent Plus) y regiones según SLA latencia.
- Definir esquema particionado antes de cargar datos para evitar hot shards.
- Habilitar PostgreSQL interface si tu stack ya usa PG drivers.
- Configurar alertas de cuota (CPU, storage, I/O) en Cloud Monitoring.
- Probar Data Boost + BigQuery external table para informes sin ETL.
- Revisar tiered storage políticas: históricos en HDD, activos en SSD.
- Ejercitar fail-over DR semestralmente (Global Database split).
Google Cloud Spanner ofrece la rara combinación de SQL relacional, consistencia transaccional global y escalado ilimitado. Con las incorporaciones de Data Boost, tiered storage y el interface PostgreSQL, Spanner se refuerza como el ejemplo de base de datos relacional cloud-native para SaaS que deben atender a millones de usuarios con mínimos tiempos de inactividad—siempre que tu presupuesto y estrategia acepten la dependencia de Google Cloud.
CockroachDB
Motor “NewSQL” inspirado en Google Spanner que ofrece consistencia transaccional fuerte, escalado horizontal y la libertad de desplegarse on-premise o en la nube (CockroachDB Cloud y Serverless).
| Aspecto | Detalle |
|---|---|
| Licencia | BSL 1.1 → pasa a Apache 2.0 3 años después de cada versión; capas Enterprise bajo Cockroach Community License opensourceforu.com |
| Versión estable (jun 2025) | CockroachDB 25.2 – +41 % de eficiencia, vector indexing “C-SPANN” y refuerzos de seguridad multi-cloud venturebeat.comprnewswire.com |
| Multi-región | Configuración declarativa de tablas/DB; SLA 99.999 % con réplicas sincronizadas cockroachlabs.com |
| Serverless | CockroachDB Cloud Serverless (99.99 % SLA) con escalado elástico y CDC nativo cockroachlabs.comcockroachlabs.com |
| Cambio continuo | Changefeeds (CDC) a Kafka/S3/PubSub sin impacto OLTP cockroachlabs.com |
Ventajas clave
- Consistencia global con latencias predecibles mediante el reloj híbrido HLC y consenso Raft.
- Escalado lineal + re-balance automático: añadir nodos (k8s, bare-metal o cloud) incrementa QPS sin particionar manualmente.
- Vector Indexing (25.2) habilita búsqueda semántica y RAG sobre miles de millones de vectores distribuidos, con +41 % de eficiencia operativa cockroachlabs.comai-techpark.com.
- Serverless gratis para prototipos; paga-por-uso en producción con 99.99 % SLA y CDC/backup incluidos cockroachlabs.com.
Desventajas o limitaciones
- Precio Enterprise: funciones avanzadas (geo-partitioning automático, encryption at rest FIPS, disaster-recovery instantaneo) requieren licencia comercial.
- Sobrecoste inicial frente a Postgres/MySQL para cargas pequeñas; cada nodo mínimo consume recursos fijos.
- Algunas extensiones PG (p. ej.
pgcrypto, triggers complejos) aún no están soportadas en el modo PostgreSQL dialect.
Arquitectura típica híbrida (on-prem + edge cloud)
textCopiarEditar ┌──────── Region A ────────┐
│ Node 1 │ Node 2 │
Clients ─┤ Voters │ Voters │
(.NET / │ │ │
Go / JS)│ ▼ │
│ Node 3 (Witness) │
└──────────┬───────────────┘
│ Raft / KV
┌──────── Region B ────────┐
│ Node 4 (Voter) │
│ Node 5 (Learner, Read-only) ──► Analytics
└──────────────────────────┘
Las lecturas locales obtienen latencia < 5 ms; si Region A falla, Region B toma el liderazgo sin intervención humana.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
Declarar multi-región (ALTER DATABASE ... PRIMARY REGION;) | Optimiza latencia y coloca réplicas automáticamente cockroachlabs.com |
| Range Partitioning + ZONE configs | Evita hot-ranges y dirige datos sensibles a jurisdicciones específicas. |
Vector index en tablas pesadas (USING VECTOR) | Recupera similitudes < 50 ms sobre 1 B embeddings cockroachlabs.com |
| Activar I/O-Optimized en Cloud | Reduce hasta 40 % el coste de almacenamiento en workloads intensivos ai-techpark.com |
| Monitorizar con DB Console & Prometheus | Detecta rebalanceos y conflictos de transacción antes de que afecten al SLA. |
Ejemplo de esquema (Fintech multi-tenant)
| Tabla | PK | Partición | Comentario |
|---|---|---|---|
tenants | tenant_id | HASH | Distribuye carga entre nodos |
accounts | (tenant_id, acct_id) | REGIONAL BY ROW | Mantiene datos cerca del usuario |
transactions | (tenant_id, txn_id) | RANGE (fecha) | Habilita CHANGEFEED para Kafka |
embeddings | vector_id | N/A | VECTOR (1536 dims) para antifraude |
Checklist rápido para tu clúster CockroachDB
- Definir topología multi-región y flag
--cluster-regional iniciar nodos. - Usar Secure Mode (certs TLS mTLS) desde el primer entorno.
- Configurar changefeeds con formato Avro/JSON para streaming a Kafka/S3.
- Probar node drain + decommission trimestralmente para validar resiliencia.
- Ajustar
kv.transaction.max_intents_bytesen ingestas masivas para evitar contention. - Activar vector indexing solo en tablas y columnas necesarias para contener el consumo de RAM.
- Revisar métricas
liveness.livenessheartbeatfailuresyreplication.queue.rebalance/transferen Prometheus.
CockroachDB 25.2 ejemplifica la visión NewSQL: transacciones ACID, consistencia fuerte y escalado global automático, todo disponible tanto on-premise como en forma de servicio serverless. Las mejoras de rendimiento (+41 %) y el nuevo vector index distribuido lo convierten en un candidato ideal para SaaS y fintech que necesitan resiliencia de nivel bancario y capacidades de IA sin abandonar SQL.
TiDB
Modelo HTAP (Hybrid-Transactional/Analytical Processing) que une OLTP + OLAP en un mismo clúster gracias a los motores TiKV (filas) y TiFlash (columnas). Compatible con MySQL 8.0, se ha convertido en la base de datos preferida por grandes plataformas de e-commerce asiáticas que gestionan eventos masivos de ventas.
| Aspecto | Detalle |
|---|---|
| Licencia | Open-source (Apache 2.0 tras 3 años, BSL 1.1 mientras tanto) + opciones Enterprise cube.asia |
| Versión estable (2025) | TiDB 8.5 GA — foreign keys GA, vector search experimental y ADMIN ALTER DDL JOBS online docs.pingcap.commydbops.com |
| Arquitectura HTAP | TiKV (row) + TiFlash (column) replicados con consistencia fuerte docs.pingcap.com |
| Serverless & Cloud | TiDB Cloud Serverless con escalado automático y generoso free tier pingcap.com |
| Casos de éxito e-commerce | Plataformas regionales migraron desde MySQL para soportar picos del Singles Day, logrando escalado lineal y analítica en tiempo real pingcap.compingcap.com |
Ventajas clave
- HTAP nativo: consultas OLAP en TiFlash sin bloquear OLTP—ideal para dashboards en vivo de inventario y ventas. docs.pingcap.com
- Escalado elástico: añadir nodos replica y balancea shards automáticamente, sin re-sharding manual. pingcap.com
- Compatibilidad MySQL: drivers, ORMs y sintaxis comunes funcionan sin cambios mayores. github.com
- Vector Search (8.5) + Full-text Search: habilita RAG y recomendaciones semánticas en el mismo clúster. pingcap.commorningstar.com
- CDC nativo (TiCDC): flujos en tiempo real a Kafka, S3 o GCS para microservicios y data lakes.
Desventajas o límites
- Curva operativa: requiere entender placement rules, replicas count y Hot Region Scheduling.
- Overhead de almacenamiento: duplicación en TiKV + TiFlash aumenta costes frente a monolitos MySQL.
- Algunas funciones MySQL (p.ej.,
MyISAM,FEDERATED) no están soportadas.
Arquitectura típica HTAP para e-commerce
textCopiarEditar┌────────────┐ gRPC/MySQL ┌────────────┐
│ Micro-API │──────────────────────►│ TiDB │ (stateless SQL)
│ (.NET/Go) │ └─────┬──────┘
└─────▲──────┘ Routed SQL/PD │ Raft + MVCC
│ ▼
│ ┌────────────┐
│ OLTP (rows) │ TiKV │ (3+ nodos)
│ └────────────┘
│ │ Async replica
▼ OLAP (columns) ▼
┌────────────┐ ┌────────────┐
│ Grafana │ ◄──── Arrow Flight ─── │ TiFlash │
└────────────┘ (dashboards <1 s) └────────────┘
▲
TiCDC │ Changefeed
▼
Kafka / S3 → Spark / Flink jobs
Los motores comparten datos con consistencia fuerte; TiFlash responde a analítica sin afectar transacciones y TiCDC alimenta pipelines de eventos.
Buenas prácticas de rendimiento
| Acción | Impacto |
|---|---|
Placement Rules: ALTER TABLE … PRIMARY_REGION="ap-southeast-1"; | Minimiza latencia en e-commerce multi-país |
TiFlash replicas = 2 + learner nodes | Acelera OLAP y protege ante fallos de zona |
tiflash max_threads acorde a núcleos | Evita contención en picos de analítica |
| AUTO ANALYZE + SQL Bindings | Planes estables en promociones flash |
| Activar Vector Search solo en tablas de catálogo | Controla uso de RAM y S3 caching |
Ejemplo de esquema (Marketplace B2C)
| Tabla | PK | Motor | Partición | Comentario |
|---|---|---|---|---|
products | prod_id | TiKV | HASH | Meta de catálogo |
orders | order_id | TiKV | RANGE (mes) | OLTP crítico |
order_items | (order_id,item_id) | TiKV | N/A | FK a productos |
pv_events | event_id | TiFlash | RANGE (día) | Click-stream para analítica HTAP |
embeddings | emb_id | TiKV | N/A | VECTOR(1536) para recomendador |
Checklist rápido para tu clúster TiDB
- Definir replicas=3 en producción; al menos 1 TiFlash por zona.
- Configurar TiDB Operator si despliegas en Kubernetes.
- Activar Auto-Scale Serverless (gratis 5 GB) para entornos dev.
- Usar Changefeeds a Kafka para microservicios de inventario en tiempo real.
- Revisar Hot Regions en DB Console y habilitar
scatter-region. - Evaluar vector search (8.5) para búsquedas semánticas y RAG.
- Programar
FULL BACKUP … TO "s3://bucket"semanal con compresión LZ4.
TiDB 8.5 se posiciona como el ejemplo HTAP por excelencia: reúne la familiaridad de MySQL con un esqueleto distribuido que escala linealmente y ejecuta analítica en segundos sobre los mismos datos transaccionales. Para gigantes del e-commerce asiático—donde picos como el Singles Day pueden multiplicar el tráfico por 10—su capacidad de auto-balanceo, vector search y serverless lo convierten en una inversión clave para 2025 y más allá.
Estudio de caso: Optimización de un e-commerce con PostgreSQL
Contexto (2024): La tienda online GreenMarket sufría latencias > 800 ms y pérdida de pedidos en hora punta.
Optimización integral de la tienda GreenMarket con PostgreSQL 15 + pgvector (2024-2025)
| Fase | Fecha | Objetivo | KPI clave | Resultado |
|---|---|---|---|---|
| Diagnóstico | Ene 2024 | Identificar cuellos de botella | TTFB, tasa de fallos 2 % | Confirmada latencia > 800 ms |
| Diseño | Feb-Mar 2024 | Modelo 3FN + estrategia de partición | Diagrama entidad-relación aprobado | — |
| Ejecución | Abr-Ago 2024 | Normalizar, particionar, desplegar réplicas | CI/CD verde | 0 errores críticos |
| Migración pgvector | Sep 2024 | Recomendador in-DB (RAG) | Tiempo de inferencia < 50 ms | Alcanzado |
| Resultados | Q1 2025 | Rendimiento, fiabilidad, ingresos | -85 % latencia, 0.1 % fallos | +27 % YoY |
Contexto y retos iniciales (Ene 2024)
- Infra anterior: VM única (n2-standard-8) en GCE con PostgreSQL 12, sin índices compuestos; tablas
productsyinventoryduplicaban 350 000 filas. - Síntomas:
- Time to first byte (TTFB) > 800 ms en picos (Black Friday, Navidad).
- Pérdida de pedidos (~2 %) por bloqueos en
orders. - Recomendaciones de producto servidas por microservicio externo (latencia > 300 ms).
Diagnóstico exhaustivo
| Herramienta | Hallazgos clave |
|---|---|
pg_stat_statements | SELECT * FROM products WHERE sku = … ejecutada 19 M veces sin índice. |
auto_explain | Escaneos secuenciales de 3 GB en inventory. |
pg_locks | 65 % de bloqueos por orders en hora punta. |
pgbench | TPS medio 230; target mínimo 1 000 TPS. |
Plan de acción
- Normalización a 3FN
- Fusionar
products+inventory(evitaUPDATEduplicados). - Crear tabla
stock_movementspara auditoría, FK aproducts.
- Fusionar
- Particionamiento mensual en
orderssqlCopiarEditarALTER TABLE orders PARTITION BY RANGE (created_at); CREATE TABLE orders_2024_01 PARTITION OF orders FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); - Read Replicas multi-AZ
- GCP regions:
us-central1(primary) + réplicas enus-central1-byus-central1-c. - Load balancer de capa 4 con health checks basados en
pg_isready.
- GCP regions:
- Upgrade → PostgreSQL 15
- Migración con
pg_upgrade –-link+ logical replication 5 min de downtime. - Habilitar page checksum y
track_io_timing.
- Migración con
- Recomender en-base con
pgvector- Tabla
product_embeddings(dim 1536); HNSW index (lists=500). - Query típica: sqlCopiarEditar
SELECT id, dot_product(embedding, $1) AS score FROM product_embeddings ORDER BY score DESC LIMIT 6;
- Tabla
- Tuning final ParámetroAntesDespués
shared_buffers2 GB6 GBwork_mem4 MB32 MBmax_wal_size1 GB4 GBrandom_page_cost4.01.1
Arquitectura resultante
textCopiarEditar ┌──────── GCLB (L4) ────────┐
│ │ │
Read Pool Read Pool Write Pool
Replica 1 Replica 2 Primary
(us-c1-b) (us-c1-c) (us-c1-a)
│ │ │
┌────────────┴───────────┴───────────────┘
│ pgvector │
│ Particionado orders │
└────────────────┬───────────────────────┘
▼
Daily logical backup to GCS
Métricas post-optimización (Mar 2025)
| KPI | Inicio 2024 | Mar 2025 | Mejora |
|---|---|---|---|
| Latencia media TTFB | 820 ms | 120 ms | -85 % |
| Pedidos fallidos | 2 % | 0.1 % | -95 % |
| TPS pico | 230 | 1 650 | ×7.2 |
| Recomendaciones | 310 ms | 45 ms | -86 % |
| Ingresos Q1 YoY | — | +27 % | — |
Costos y ROI
- Infra: de 1 VM n2-standard-8 a 1 primary n2-standard-16 + 2 replicas n2-standard-8 (≈ +48 % costo).
- ROI: incremento de ingresos trimestrales (≈ USD 480 k) cubre extra OPEX en 11 días.
Lecciones y mejores prácticas
- Normalización primero, caché después: reducir redundancia simplificó lógica y habilitó índices eficientes.
- Particiona según patrón de acceso: rango mensual en
ordersgarantizó pruning y backups diferenciales rápidos. - Replicas ≠ solo DR: balancear lecturas al 70 % liberó CPU del primario.
- Vector search in-DB simplificó arquitectura (se retiró microservicio Python, menos latencia y costes).
- Monitoriza los basics:
pg_stat_io,pg_stat_statements, Grafana + Prometheus detectan regresiones antes de que impacten ventas.
Próximos pasos (2025-2026)
- Aurora PG compat en evaluación para burst de temporada.
- Implementar row-level-security por país (cumplimiento GDPR / LGPD).
- Explorar pg_bm25 para búsqueda full-text y subida de conversión.
Conclusión: con una estrategia centrada en modelado correcto, partición, réplicas y capacidades vectoriales, GreenMarket transformó su plataforma, pasando de ser un cuello de botella comercial a un motor capaz de escalar campañas globales sin sacrificar la experiencia de usuario ni la integridad transaccional.
Conclusión
Las bases de datos relacionales siguen dominando proyectos que exigen transacciones consistentes y análisis estructurado. Con ejemplos como PostgreSQL o CockroachDB, combinamos robustez histórica con innovación NewSQL. Empieza hoy mismo revisando tu esquema y aplicando el checklist siguiente.
Checklist on-page
- Verificar claves primarias y foráneas correctas.
- Revisar índices y eliminar los redundantes.
- Aplicar normalización hasta 3FN.
- Configurar backups automáticos y tests de restauración.
- Monitorizar métricas de latencia (<200 ms).
- Usar imágenes WebP y
loading="lazy"para diagramas. - Añadir enlaces internos a modelo relacional y normalización de bases de datos.
- Incluir enlaces externos a https://www.postgresql.org/docs/ y https://dev.mysql.com/doc/.
- Actualizar esta guía cada 6 meses para reflejar nuevas versiones.

Glosario Completo de Términos de Bases de Datos: Guía Definitiva para Profesionales y Estudiantes
Los términos de bases de datos son fundamentales para cualquier profesional que trabaje con tecnología…
Bases de Datos Jerárquicas: la Estructura Troncal de la Información
En un mundo impulsado por datos, comprender cómo se organizan y gestionan es fundamental. Desde…

Poderosas Bases de Datos en Excel: Domina la Toma de Decisiones Estratégicas
¿Te ha pasado que abres una hoja de cálculo de Excel y te encuentras con…

Dominando las Bases de Datos de Ventas en Excel: Avanzando a Decisiones Estratégicas
Laura, gerente de ventas de una pequeña empresa de distribución de productos orgánicos en Bucaramanga,…

Tipos de Bases de Datos: una Elección entre Equilibrio, Funcionalidad, Rendimiento, Costo y Gestión
En la era digital actual, donde cada interacción, cada transacción y cada byte de información…

Bases de Datos XML: ¿Habilitadas o Nativas? Desentrañando el Almacenamiento y Gestión de Datos Jerárquicos en la Era Digital
En el vasto universo del Big Data y la analítica de datos, la elección de…