En la era digital actual, los datos se han convertido en el nuevo oro. Cada día, generamos una cantidad asombrosa de información a través de nuestras interacciones en línea, dispositivos conectados y sistemas empresariales. Esta explosión de datos ha dado lugar a la necesidad de bases de datos masivas capaces de almacenar, procesar y analizar volúmenes de información que hace apenas una década habrían sido inimaginables.
En este artículo, exploraremos las 10 bases de datos más grandes del mundo en 2024, examinando no solo su tamaño impresionante, sino también su propósito, tecnología subyacente y el impacto que tienen en nuestras vidas cotidianas y en el avance de la ciencia y la tecnología.
El Panorama del Big Data en 2024
Antes de sumergirnos en nuestra lista de las bases de datos más grandes, es importante comprender el contexto en el que operan. El término “Big Data” se ha convertido en un concepto omnipresente en el mundo tecnológico, refiriéndose no solo a la cantidad de datos, sino también a la variedad, velocidad y veracidad de la información que se maneja.
En 2024, nos encontramos en un punto donde el volumen de datos generados globalmente se mide en zettabytes (1 ZB = 1 billón de gigabytes). Esta escala masiva ha llevado a innovaciones significativas en tecnologías de almacenamiento, procesamiento distribuido y análisis de datos, permitiendo a organizaciones de todos los tamaños aprovechar el poder de sus datos como nunca antes.
Las 10 Bases de Datos Más Grandes del Mundo
1. World Data Center for Climate (WDCC)
- Tamaño estimado: 140+ petabytes
- Ubicación: Hamburgo, Alemania
- Uso: Almacenamiento y análisis de datos climáticos globales
El WDCC, operado por el Centro Alemán de Computación Climática (DKRZ), es un tesoro de información climática. Alberga datos de observaciones atmosféricas, oceánicas y terrestres, así como resultados de modelos climáticos complejos.
La importancia del WDCC en la lucha contra el cambio climático no puede subestimarse. Sus vastos repositorios de datos permiten a los científicos analizar tendencias climáticas a largo plazo, desarrollar modelos predictivos más precisos y proporcionar evidencia crucial para la formulación de políticas ambientales globales.
El centro utiliza sistemas de almacenamiento de alta performance y tecnologías de computación avanzadas para manejar y procesar estos enormes volúmenes de datos. Su infraestructura incluye supercomputadoras capaces de realizar simulaciones climáticas complejas que ayudan a predecir escenarios futuros y evaluar el impacto de diversas estrategias de mitigación del cambio climático.
2. Amazon Web Services (AWS)
- Tamaño estimado: 100+ petabytes
- Ubicación: Distribuida globalmente
- Uso: Plataforma de nube que aloja innumerables bases de datos para empresas globales
AWS, el gigante de la computación en la nube de Amazon, no es una base de datos única, sino un vasto ecosistema de servicios de almacenamiento y procesamiento de datos. Su tamaño combinado lo coloca entre las infraestructuras de datos más grandes del mundo.
AWS ofrece una variedad de servicios de bases de datos, incluyendo Amazon RDS, DynamoDB, y Redshift, que atienden a millones de clientes en todo el mundo. Desde startups hasta corporaciones Fortune 500, innumerables organizaciones confían en AWS para almacenar y procesar sus datos críticos.
La infraestructura de AWS está diseñada para ofrecer alta disponibilidad, escalabilidad y seguridad. Utiliza tecnologías avanzadas como el almacenamiento en capas, la replicación entre regiones y la encriptación de datos en reposo y en tránsito para garantizar la integridad y accesibilidad de los datos de sus clientes.
3. Facebook (Meta)
- Tamaño estimado: 300+ petabytes
- Ubicación: Centros de datos distribuidos globalmente
- Uso: Almacenamiento de datos de usuarios, interacciones y contenido multimedia
Facebook, ahora parte de Meta, maneja una de las bases de datos de usuarios más grandes del mundo. Con miles de millones de usuarios activos, la plataforma procesa y almacena una cantidad astronómica de datos diariamente, incluyendo publicaciones, likes, comentarios, fotos y videos.
La infraestructura de datos de Facebook es un marvel de la ingeniería moderna. Utiliza una combinación de tecnologías propietarias y de código abierto para manejar su carga masiva de datos. Esto incluye Cassandra para el almacenamiento distribuido, Presto para consultas SQL a gran escala, y Hive para el análisis de big data.
Facebook ha sido pionero en varias tecnologías de bases de datos, como RocksDB, un motor de almacenamiento de clave-valor optimizado para rendimiento en SSD. También ha desarrollado herramientas como Tupperware para la gestión de contenedores y Twine para la programación de trabajos, que son fundamentales para manejar su infraestructura de datos a escala.
4. Google
- Tamaño estimado: 15+ exabytes
- Ubicación: Centros de datos distribuidos globalmente
- Uso: Indexación web, almacenamiento de datos de usuarios y servicios como Gmail, Google Drive, etc.
Google, el gigante de la búsqueda y la tecnología, maneja una de las bases de datos más grandes y diversas del mundo. Su tamaño estimado de 15+ exabytes es difícil de comprender: equivale a 15 millones de terabytes o 15 mil millones de gigabytes.
La base de datos de Google no solo almacena el índice de búsqueda más grande del mundo, sino también los datos de sus numerosos servicios como Gmail, Google Drive, Google Photos, y YouTube (que tiene su propia entrada en esta lista debido a su tamaño masivo).
Google ha sido pionero en numerosas tecnologías de bases de datos y procesamiento distribuido. Algunas de las más notables incluyen:
- BigTable: Una base de datos distribuida para el almacenamiento de datos estructurados a gran escala.
- Spanner: Un sistema de base de datos distribuida globalmente que proporciona consistencia fuerte en escala planetaria.
- MapReduce: Un modelo de programación para el procesamiento y generación de grandes conjuntos de datos.
Estas tecnologías, muchas de las cuales Google ha compartido con la comunidad de código abierto, han revolucionado la forma en que se manejan los datos a escala masiva en toda la industria.
5. Large Hadron Collider (LHC) en CERN
- Tamaño estimado: 530+ petabytes
- Ubicación: Ginebra, Suiza
- Uso: Almacenamiento de datos de experimentos físicos de partículas
El Gran Colisionador de Hadrones (LHC) del CERN es el acelerador de partículas más grande y potente del mundo. Los experimentos realizados en el LHC generan cantidades masivas de datos que deben ser almacenados y analizados.
La base de datos del LHC es única en su clase. Almacena datos de colisiones de partículas que ocurren a velocidades cercanas a la de la luz, capturando eventos que duran apenas fracciones de segundo pero que pueden proporcionar información crucial sobre los fundamentos del universo.
Para manejar este flujo masivo de datos, el CERN ha desarrollado el Worldwide LHC Computing Grid, una red de computación distribuida que conecta centros de datos en todo el mundo. Esta infraestructura permite a los científicos acceder y analizar datos del LHC desde cualquier parte del planeta.
Los datos del LHC han llevado a descubrimientos revolucionarios en física de partículas, incluyendo la confirmación experimental del bosón de Higgs en 2012, un hallazgo que llevó al Premio Nobel de Física en 2013.
6. National Security Agency (NSA)
- Tamaño estimado: Yottabytes (clasificado)
- Ubicación: Estados Unidos (múltiples sitios)
- Uso: Almacenamiento de datos de inteligencia y seguridad nacional
La Agencia de Seguridad Nacional de los Estados Unidos opera una de las bases de datos más grandes y más secretas del mundo. Aunque el tamaño exacto es clasificado, se especula que podría alcanzar el rango de los yottabytes (1 YB = 1 trillón de terabytes).
La NSA recopila y analiza vastas cantidades de datos de comunicaciones globales como parte de sus operaciones de inteligencia y ciberseguridad. Esto incluye metadatos de llamadas telefónicas, correos electrónicos, mensajes de texto y tráfico de Internet.
La infraestructura de datos de la NSA es un tema de mucha especulación y controversia. Se sabe que utiliza tecnologías de vanguardia en criptografía, análisis de big data y computación cuántica. El centro de datos de Utah de la NSA, conocido como el “Titán Cibernético”, es una instalación masiva diseñada para almacenar y procesar cantidades enormes de datos.
El tamaño y alcance de la base de datos de la NSA ha sido objeto de debates sobre privacidad y vigilancia, especialmente después de las revelaciones de Edward Snowden en 2013.
7. YouTube
- Tamaño estimado: 1000+ petabytes
- Ubicación: Centros de datos de Google distribuidos globalmente
- Uso: Almacenamiento y transmisión de contenido de video
YouTube, propiedad de Google, es el sitio de compartición de videos más grande del mundo y, consecuentemente, alberga una de las bases de datos de contenido multimedia más extensas que existen.
Cada minuto, se suben cientos de horas de nuevo contenido a YouTube, lo que resulta en un crecimiento constante y masivo de su base de datos. Este contenido varía desde videos caseros hasta producciones profesionales de alta calidad, abarcando prácticamente todos los temas imaginables.
La infraestructura de YouTube está diseñada para manejar no solo el almacenamiento de esta cantidad masiva de datos, sino también para servir miles de millones de streams de video simultáneamente a usuarios en todo el mundo. Esto requiere una combinación de almacenamiento eficiente, estrategias de caching avanzadas y una red de distribución de contenido (CDN) global.
YouTube utiliza tecnologías de compresión de video avanzadas para optimizar el almacenamiento y la transmisión de datos. También emplea algoritmos de aprendizaje automático para tareas como la generación automática de subtítulos, la detección de contenido inapropiado y la recomendación de videos a los usuarios.
8. Internet Archive
- Tamaño estimado: 70+ petabytes
- Ubicación: San Francisco, California, EE.UU.
- Uso: Preservación de copias históricas de páginas web y otros contenidos digitales
El Internet Archive es una biblioteca digital sin fines de lucro con la misión de proporcionar “acceso universal a todo el conocimiento”. Su proyecto más conocido es la Wayback Machine, que archiva versiones históricas de sitios web.
La base de datos del Internet Archive no solo incluye copias de sitios web, sino también libros, audio, video, imágenes y software. Es un recurso invaluable para investigadores, historiadores y cualquier persona interesada en la evolución de la web y la cultura digital.
El desafío único del Internet Archive es mantener no solo los datos, sino también las tecnologías necesarias para acceder a formatos de archivo antiguos y obsoletos. Esto implica la preservación de hardware y software históricos junto con los datos mismos.
El Internet Archive utiliza sistemas de almacenamiento redundante y distribuido para garantizar la preservación a largo plazo de sus datos. También colabora con bibliotecas y archivos de todo el mundo para ampliar su colección y mejorar el acceso a la información digital histórica.
9. Spotify
- Tamaño estimado: 100+ petabytes
- Ubicación: Centros de datos distribuidos globalmente (principalmente en Google Cloud)
- Uso: Almacenamiento y transmisión de música y podcasts
Spotify, el servicio de streaming de música líder en el mundo, maneja una base de datos masiva que incluye millones de pistas de audio, datos de usuarios y metadatos asociados.
La base de datos de Spotify no solo almacena archivos de audio, sino también una gran cantidad de datos relacionados, como letras de canciones, información de artistas, datos de reproducción de usuarios, y los complejos algoritmos que impulsan sus sistemas de recomendación.
Spotify utiliza una arquitectura de microservicios y tecnologías de bases de datos distribuidas para manejar su enorme volumen de datos y tráfico de usuarios. Esto incluye el uso de Cassandra para el almacenamiento de datos a gran escala y sistemas de procesamiento de eventos en tiempo real para manejar las interacciones de los usuarios y las actualizaciones de datos.
La compañía también ha sido pionera en el uso de técnicas avanzadas de análisis de datos y aprendizaje automático para mejorar la experiencia del usuario, incluyendo la generación de listas de reproducción personalizadas y la identificación de nuevas tendencias musicales.
10. Wayback Machine
- Tamaño estimado: 70+ petabytes
- Ubicación: San Francisco, California, EE.UU. (parte del Internet Archive)
- Uso: Archivo de versiones históricas de sitios web
Aunque técnicamente es parte del Internet Archive, la Wayback Machine merece una mención especial debido a su importancia y tamaño. Este proyecto tiene como objetivo crear un registro histórico de la World Wide Web, capturando y archivando versiones de sitios web a lo largo del tiempo.
La Wayback Machine contiene cientos de miles de millones de capturas web, que datan desde 1996 hasta el presente. Este vasto archivo proporciona una visión única de cómo ha evolucionado la web y cómo han cambiado sitios específicos a lo largo del tiempo.
El desafío técnico de la Wayback Machine va más allá del simple almacenamiento de datos. Implica la captura regular de sitios web, la indexación de este contenido para que sea buscable, y la capacidad de renderizar versiones antiguas de sitios web que pueden usar tecnologías obsoletas.
La Wayback Machine es una herramienta invaluable para investigadores, periodistas, historiadores y cualquier persona interesada en la historia digital. Ha sido utilizada en procesos legales, investigaciones periodísticas y estudios académicos sobre la evolución de internet y la sociedad digital.
LOS 5 CENTROS DE DATOS MÁS GRANDES DEL MUNDO
La nube se ha convertido en una parte integral de nuestras vidas, a menudo sin que nos demos cuenta. Desde guardar una cita en Google Calendar hasta preguntarle algo a Siri o Alexa, desde compartir fotos en redes sociales hasta navegar por tiendas en línea, e incluso al enviar mensajes por WhatsApp o Telegram, todos interactuamos con la nube diariamente.
Esta omnipresencia digital genera una demanda masiva de almacenamiento y procesamiento de datos. Para satisfacer esta necesidad, surgen los Centros de Procesamiento de Datos (CDP), también conocidos como datacenters. Estos son vastos complejos llenos de servidores y sistemas de enfriamiento, diseñados para manejar enormes volúmenes de información.
Desafíos y Tecnologías en el Manejo de Bases de Datos Masivas
El manejo de bases de datos a esta escala presenta desafíos únicos que han impulsado innovaciones significativas en tecnología de la información. Algunos de los principales desafíos y las tecnologías desarrolladas para abordarlos incluyen:
1. Escalabilidad
Para manejar volúmenes de datos que crecen exponencialmente, las organizaciones han adoptado arquitecturas distribuidas y tecnologías de escalado horizontal. Bases de datos NoSQL como Cassandra, MongoDB y HBase se han vuelto populares por su capacidad de escalar fácilmente añadiendo más nodos a un cluster.
2. Consistencia y Disponibilidad
El teorema CAP sugiere que es imposible para un sistema de datos distribuido proporcionar simultáneamente Consistencia, Disponibilidad y Tolerancia a particiones. Diferentes bases de datos hacen diferentes compensaciones en este aspecto. Por ejemplo, Google’s Spanner intenta proporcionar una fuerte consistencia global, mientras que Cassandra ofrece consistencia eventual con alta disponibilidad.
3. Procesamiento y Análisis en Tiempo Real
Con el crecimiento del Internet de las Cosas (IoT) y la necesidad de insights en tiempo real, se han desarrollado tecnologías como Apache Kafka, Apache Flink y Apache Spark Streaming para procesar y analizar grandes volúmenes de datos en tiempo real.
4. Seguridad y Privacidad
Con el aumento de las regulaciones de privacidad como el GDPR, las organizaciones deben implementar medidas robustas de seguridad y privacidad. Esto ha llevado al desarrollo de tecnologías de encriptación avanzadas, sistemas de control de acceso granulares y técnicas de anonimización de datos.
5. Almacenamiento Eficiente
Para manejar petabytes o exabytes de datos, se han desarrollado tecnologías de compresión avanzadas y sistemas de almacenamiento en capas que mueven automáticamente datos menos accedidos a almacenamiento más barato y lento.
El Futuro de las Bases de Datos Masivas
A medida que avanzamos hacia el futuro, podemos esperar que las bases de datos continúen creciendo en tamaño y complejidad. Algunas tendencias que probablemente darán forma al futuro de las bases de datos masivas incluyen:
1. Inteligencia Artificial y Aprendizaje Automático
La IA y el ML no solo generarán más datos, sino que también se utilizarán para optimizar el rendimiento de las bases de datos, automatizar tareas de administración y extraer insights más profundos de los datos.
2. Edge Computing
Con el crecimiento del IoT, veremos más procesamiento y almacenamiento de datos ocurriendo en el “edge” (cerca de la fuente de los datos), lo que podría llevar a arquitecturas de bases de datos más distribuidas y descentralizadas.
3. Bases de Datos Cuánticas
A medida que la computación cuántica avanza, podríamos ver el desarrollo de bases de datos cuánticas capaces de manejar y procesar volúmenes de datos aún mayores con una eficiencia sin precedentes.
4. Blockchain y Bases de Datos Descentralizadas
Las tecnologías blockchain están llevando a nuevos modelos de bases de datos descentralizadas que podrían cambiar la forma en que pensamos sobre el almacenamiento y la verificación de datos.
5. Automatización y Bases de Datos Autónomas
Las bases de datos del futuro podrían ser en gran medida autónomas, capaces de autooptimizarse, autorepararse y autoprotegerse con mínima intervención humana.
Conclusión
Las 10 bases de datos más grandes del mundo en 2024 son un testimonio del increíble volumen de información que generamos y consumimos en la era digital. Desde el clima global hasta nuestras interacciones sociales, desde los secretos del universo hasta la historia de la web, estas bases de datos no solo almacenan información, sino que también impulsan innovaciones, informan decisiones y dan forma a nuestro entendimiento del mundo.
A medida que avanzamos, el manejo eficiente y ético de estos vastos repositorios de datos será crucial. Los desafíos son enormes, pero también lo son las oportunidades. El futuro de las bases de datos masivas promete no solo un crecimiento continuo en volumen, sino también avances significativos en cómo procesamos, analizamos y extraemos valor de estos datos.
En última instancia, el verdadero poder de estas bases de datos masivas no reside simplemente en su tamaño, sino en cómo utilizamos la información que contienen para impulsar el progreso científico, mejorar nuestras vidas y abordar los desafíos globales que enfrentamos como sociedad.
A medida que nos adentramos en esta nueva frontera de la gestión de datos, será crucial mantener un equilibrio entre la innovación tecnológica y consideraciones éticas como la privacidad y la seguridad. El futuro de las bases de datos masivas es brillante y lleno de posibilidades, y sin duda continuará siendo un campo fascinante para observar en los años venideros.
Glosario Completo de Términos de Bases de Datos: Guía Definitiva para Profesionales y Estudiantes
Los términos de bases de datos son fundamentales para cualquier profesional que trabaje con tecnología…
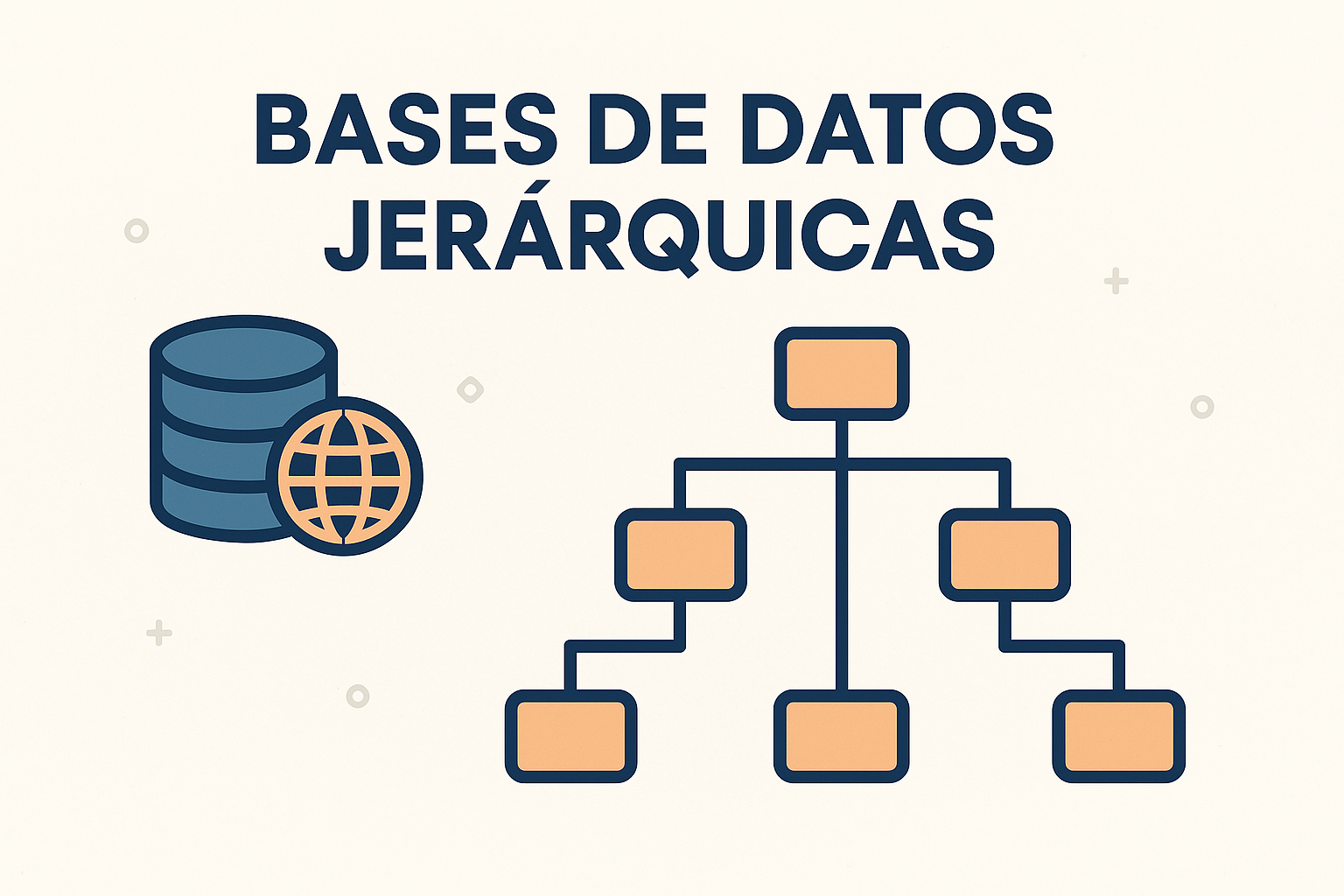
Bases de Datos Jerárquicas: la Estructura Troncal de la Información
En un mundo impulsado por datos, comprender cómo se organizan y gestionan es fundamental. Desde…

Poderosas Bases de Datos en Excel: Domina la Toma de Decisiones Estratégicas
¿Te ha pasado que abres una hoja de cálculo de Excel y te encuentras con…

Dominando las Bases de Datos de Ventas en Excel: Avanzando a Decisiones Estratégicas
Laura, gerente de ventas de una pequeña empresa de distribución de productos orgánicos en Bucaramanga,…

Tipos de Bases de Datos: una Elección entre Equilibrio, Funcionalidad, Rendimiento, Costo y Gestión
En la era digital actual, donde cada interacción, cada transacción y cada byte de información…

Bases de Datos XML: ¿Habilitadas o Nativas? Desentrañando el Almacenamiento y Gestión de Datos Jerárquicos en la Era Digital
En el vasto universo del Big Data y la analítica de datos, la elección de…