¿Qué es una base de datos y cómo se puede entender?, en términos sencillos, como una herramienta fundamental para la recopilación y organización de información. Su capacidad para almacenar datos sobre una amplia gama de temas, desde personas y productos hasta pedidos y más, la convierte en un recurso versátil para diversas necesidades. Inicialmente, muchas bases de datos pueden comenzar de forma modesta, quizás como una simple lista dentro de un documento de texto o una hoja de cálculo. Sin embargo, a medida que la cantidad y la complejidad de la información crecen, la necesidad de una estructura más robusta y organizada se hace evidente, lo que lleva a la adopción de sistemas de bases de datos dedicados. Database basics
En un sentido más técnico, una base de datos se define como una colección organizada de información estructurada, que se almacena típicamente de forma electrónica dentro de un sistema informático. Se trata de una colección sistemática de datos que se guarda en formato electrónico, lo que facilita su acceso, gestión y manipulación. Esta capacidad de almacenamiento electrónico permite albergar una gran variedad de tipos de datos, incluyendo texto, números, imágenes, videos y archivos de diversa índole. Las bases de datos son esenciales para el funcionamiento interno de las empresas, ya que soportan sus operaciones diarias y registran las interacciones con clientes y proveedores. Además, contienen información administrativa crucial y datos más especializados, como modelos económicos o de ingeniería. Para visualizar su estructura básica, se puede pensar en una base de datos simple como un conjunto de hojas de cálculo o tablas que se han conectado de una manera lógica y sistemática.
La transición observada desde el uso de listas y hojas de cálculo hasta la implementación de sistemas de bases de datos más sofisticados pone de manifiesto una clara necesidad de mejorar la organización y la eficiencia en la gestión de la información, especialmente cuando los volúmenes de datos experimentan un crecimiento significativo. Las formas primarias de almacenamiento de datos, aunque útiles en sus inicios, presentaban limitaciones inherentes para manejar la creciente complejidad y cantidad de información que las organizaciones comenzaron a generar y necesitar. La adopción de bases de datos representa, por lo tanto, una evolución tecnológica directa en respuesta a estos desafíos, ofreciendo soluciones diseñadas específicamente para organizar, buscar y gestionar grandes cantidades de datos de manera más efectiva.
Además, la habilidad de las bases de datos modernas para almacenar una amplia gama de tipos de datos resalta su notable versatilidad y la amplitud de su aplicabilidad en diversos campos. Inicialmente, las bases de datos se enfocaban principalmente en el almacenamiento de datos estructurados, como texto y números. Sin embargo, el avance tecnológico y la creciente importancia del contenido digital, incluyendo imágenes, videos y otros formatos, generaron la necesidad de que las bases de datos pudieran manejar también estos tipos de datos no estructurados y semiestructurados. Esta expansión en la capacidad de almacenamiento, impulsada en gran medida por las demandas de las aplicaciones contemporáneas, subraya la adaptabilidad de las bases de datos a las necesidades cambiantes del panorama digital.

- Los Componentes Fundamentales: Entendiendo la Estructura
- Un Abanico de Posibilidades: Explorando los Tipos de Bases de Datos
- Aplicaciones en el Mundo Real: ¿Dónde se Utilizan las Bases de Datos?
- El Motor Interno: Sistemas de Gestión de Bases de Datos (SGBD)
- Comunicándose con los Datos: Introducción a los Lenguajes de Consulta
- Ejemplos Prácticos: Consultas SQL Básicas en Acción
- La Columna Vertebral de la Información: Importancia de las Bases de Datos
- Organización y Gestión Eficiente de Datos:
- Recuperación Rápida y Eficaz de Información:
- Integridad y Precisión de los Datos:
- Seguridad y Protección de Datos:
- Escalabilidad y Adaptabilidad:
- Copia de Seguridad y Recuperación ante Desastres:
- Compartición de Datos Optimizada:
- Mejora del Rendimiento:
- Cumplimiento Normativo:
- Impulsando Decisiones Inteligentes: El Papel de las Bases de Datos en la Toma de Decisiones
- El Panorama Actual: Tendencias Emergentes en el Mundo de las Bases de Datos
- Bases de Datos de Grafos:
- El Presente y Futuro de la Gestión de Datos
Los Componentes Fundamentales: Entendiendo la Estructura
Tablas, Registros y Campos: La Base de la Organización
Una característica fundamental de las bases de datos es su capacidad para albergar múltiples tablas dentro de una misma estructura. Cada una de estas tablas se asemeja en su presentación a una hoja de cálculo, donde la información se dispone de manera ordenada en filas y columnas. Esta organización tabular constituye la base sobre la cual se construye la estructura lógica de la base de datos.
Dentro de cada tabla, cada fila individual recibe el nombre de registro. Es en los registros donde se almacena cada pieza particular de información. A su vez, cada registro se compone de uno o más campos, los cuales se corresponden directamente con las columnas de la tabla. Es importante destacar que cada campo debe ser definido con un tipo de dato específico, que puede ser texto, fecha, hora, número, entre otros. Esta designación de tipo de dato asegura la consistencia y la integridad de la información almacenada. Adicionalmente, para optimizar la eficiencia y evitar la duplicidad de la información dentro de la base de datos, se aplica un proceso denominado normalización. Este proceso consiste en organizar los datos en múltiples tablas relacionadas, de manera que cada dato se almacene únicamente una vez, minimizando así la redundancia y facilitando la gestión y actualización de la información.
Si bien la estructura de filas y columnas de una tabla de base de datos puede recordar a una hoja de cálculo, un concepto crucial que diferencia a una base de datos bien diseñada de una simple colección de datos es la normalización. Mientras que las hojas de cálculo pueden contener datos repetidos en múltiples celdas o filas, las bases de datos relacionales buscan eliminar esta redundancia a través de la división lógica de los datos en diferentes tablas relacionadas. Este proceso no solo optimiza el espacio de almacenamiento, sino que también mejora la consistencia de los datos, ya que cualquier modificación en un dato específico solo necesita realizarse en un único lugar. Además, la normalización facilita la realización de consultas complejas y la combinación de información de diferentes tablas para obtener una visión más completa y significativa de los datos.
Crear una base de datos en Xampp con MySQL y phpMyAdmin – Tutorial paso a paso en YouTube
Objetos Adicionales: Formularios, Informes, Macros y Módulos
Además de las tablas, una base de datos, especialmente en sistemas más accesibles como Microsoft Access, puede contener una variedad de objetos adicionales que extienden su funcionalidad más allá del simple almacenamiento de datos. Entre estos objetos se encuentran los formularios, que permiten a los usuarios interactuar con los datos de manera intuitiva a través de interfaces personalizadas para la entrada y edición de información. Los informes, por otro lado, se utilizan para presentar los datos de forma organizada y visualmente atractiva, facilitando su análisis y compartición en diversos formatos. Asimismo, las macros y los módulos, a menudo implementados mediante lenguajes de programación como VBA (Visual Basic for Applications), ofrecen la capacidad de automatizar tareas repetitivas y agregar lógica personalizada a la base de datos, ampliando significativamente sus capacidades y adaptándola a necesidades específicas.
Estos objetos complementarios son fundamentales para hacer que la interacción con la base de datos sea más eficiente y accesible para los usuarios. Los formularios, por ejemplo, proporcionan una abstracción de la complejidad subyacente de las tablas, permitiendo que personas sin conocimientos técnicos profundos puedan ingresar y modificar datos de manera sencilla. Los informes, por su parte, transforman los datos brutos almacenados en las tablas en información útil y comprensible, facilitando la toma de decisiones basada en el análisis de tendencias y patrones. En conjunto, estos objetos convierten una base de datos en una herramienta integral para la gestión de la información, que va más allá del mero depósito de datos y se enfoca en la interacción efectiva del usuario y la presentación clara de la información.
El Contenedor: El Archivo de la Base de Datos
En la mayoría de los casos, y a menos que se haya diseñado específicamente para interactuar con datos o código provenientes de otras fuentes externas, una base de datos suele almacenar todas sus tablas y otros objetos dentro de un único archivo. Esta característica simplifica considerablemente la gestión y el transporte de bases de datos de menor tamaño, como las utilizadas en entornos personales o pequeñas empresas. La idea de un archivo único que contiene toda la información y la estructura de la base de datos facilita su copia, traslado y administración general.
Sin embargo, es importante señalar que los sistemas de bases de datos empresariales, que manejan volúmenes de datos mucho mayores y requieren un rendimiento superior, suelen implementar arquitecturas más complejas. En estos entornos, los datos pueden distribuirse en múltiples archivos, servidores e incluso ubicaciones geográficas para optimizar la escalabilidad, la disponibilidad y la tolerancia a fallos. A pesar de esta complejidad en los sistemas de gran escala, la concepción de una base de datos como un archivo único sigue siendo útil para comprender la naturaleza autocontenida de las bases de datos más pequeñas y su relativa facilidad de gestión para usuarios generales.
Descargar base de datos de ejemplo en Excel para practicar análisis de datos
Un Abanico de Posibilidades: Explorando los Tipos de Bases de Datos
La Dominancia Relacional: Tablas y SQL
Las bases de datos relacionales representan un paradigma fundamental en el mundo de la gestión de datos, caracterizándose por la organización de la información en estructuras denominadas tablas, compuestas a su vez por filas y columnas. Este modelo ha alcanzado una gran popularidad, convirtiéndose quizás en el tipo de base de datos más extendido en su uso. Un aspecto distintivo de las bases de datos relacionales es la utilización de claves primarias y foráneas para establecer conexiones lógicas entre diferentes tablas, lo que permite modelar relaciones complejas entre los datos. What Is a Database?
Para garantizar la integridad y la fiabilidad de las operaciones, las bases de datos relacionales se adhieren a un conjunto de propiedades conocidas como ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad), que aseguran que las transacciones se procesen de manera confiable. La interacción con estas bases de datos se realiza principalmente a través de un lenguaje de consulta estandarizado denominado SQL (Structured Query Language). Las bases de datos relacionales demuestran ser particularmente eficaces en aplicaciones que requieren la ejecución de consultas complejas y la gestión de transacciones que involucran múltiples filas de datos, como es el caso de los sistemas financieros y las plataformas de comercio electrónico. Entre los ejemplos más comunes y utilizados de sistemas de gestión de bases de datos relacionales se encuentran MySQL, PostgreSQL, Oracle y Microsoft SQL Server. Types of databases: a guide for data enthusiasts
La adopción generalizada de las bases de datos relacionales en el ámbito empresarial se debe en gran medida a la claridad de su modelo de datos y a la potencia del lenguaje SQL para manipular y consultar la información. La estructura tabular facilita la comprensión y la organización de los datos, mientras que SQL proporciona un medio estandarizado y robusto para interactuar con la base de datos, permitiendo la recuperación precisa de la información y la ejecución de complejas operaciones de gestión de datos. La combinación de estas características, junto con las garantías de integridad y fiabilidad que ofrecen las propiedades ACID, ha consolidado a las bases de datos relacionales como una tecnología fundamental para muchas aplicaciones críticas.
La Flexibilidad de NoSQL: Más Allá de las Tablas
En contraste con el modelo relacional, las bases de datos NoSQL (Not Only SQL o no relacionales) emplean una variedad de modelos de datos para el acceso y la gestión de la información. Esta flexibilidad les permite almacenar y manipular datos que no se ajustan fácilmente a la estructura rígida de tablas, como datos no estructurados (por ejemplo, texto libre, imágenes, videos) y semiestructurados (por ejemplo, documentos JSON). Las bases de datos NoSQL son especialmente adecuadas para escenarios que implican el manejo de grandes volúmenes de datos, aplicaciones que requieren respuestas en tiempo real y sistemas con una alta velocidad de escritura. Una de sus ventajas clave es su capacidad de escalabilidad horizontal, lo que significa que el rendimiento puede mejorarse significativamente mediante la adición de más nodos de servidor a la infraestructura. What’s the Difference Between Relational and Non-relational Databases?
El surgimiento y la creciente popularidad de las bases de datos NoSQL responden directamente a la necesidad de flexibilidad y escalabilidad que demandan las aplicaciones web modernas, las cuales a menudo deben gestionar conjuntos de datos masivos y diversos. A diferencia de la rigidez del esquema que caracteriza a las bases de datos relacionales, los modelos de datos ofrecidos por las bases de datos NoSQL, como los basados en documentos, grafos o pares clave-valor, se adaptan de manera más eficiente a las necesidades cambiantes y a la naturaleza variada de los datos que manejan las aplicaciones contemporáneas. Esta adaptabilidad, combinada con la capacidad de escalar de forma horizontal para hacer frente a grandes volúmenes de tráfico y datos, ha convertido a las bases de datos NoSQL en una tecnología esencial para el desarrollo de aplicaciones web y móviles de alto rendimiento.
Dentro de la categoría de bases de datos NoSQL, se pueden identificar varios tipos principales, cada uno con sus propias características y casos de uso:
- Bases de Datos de Documentos: Este tipo de base de datos almacena la información en forma de documentos, que a menudo se representan como objetos JSON (JavaScript Object Notation). Estos documentos son flexibles y pueden tener una estructura jerárquica, lo que permite almacenar datos complejos de manera natural. Ejemplos populares de bases de datos de documentos incluyen MongoDB y Couchbase. El modelo de documentos simplifica el proceso de desarrollo al alinear la forma en que se almacenan los datos con las estructuras de datos que se utilizan comúnmente en el código de las aplicaciones, facilitando la serialización y deserialización de la información. Relational vs. Non-Relational Databases – Pluralsight
- Bases de Datos de Clave-Valor: En este modelo, los datos se almacenan como una colección de pares clave-valor, donde cada valor está asociado a una clave única que sirve como su identificador. Esta estructura simple permite un acceso a los datos extremadamente rápido, lo que hace que las bases de datos de clave-valor sean ideales para casos de uso como el almacenamiento en caché de datos de uso frecuente y la gestión de sesiones de usuario en aplicaciones web. Un ejemplo destacado de base de datos de clave-valor es Redis. La búsqueda directa por clave es una operación inherentemente eficiente, lo que contribuye al alto rendimiento de este tipo de bases de datos.
- Bases de Datos de Grafos: Estas bases de datos están especialmente diseñadas para almacenar y navegar por las relaciones entre diferentes entidades. Utilizan nodos para representar los objetos de datos y aristas para indicar las conexiones o relaciones entre estos objetos. Un ejemplo representativo de base de datos de grafos es Neo4j. Este tipo de base de datos resulta particularmente útil en aplicaciones donde las relaciones entre los datos son tan importantes como los datos mismos, como en redes sociales, sistemas de recomendación y análisis de redes complejas. La optimización para las relaciones permite realizar consultas complejas sobre las conexiones entre los datos de manera eficiente.
- Bases de Datos de Columnas Anchas: A diferencia de las bases de datos relacionales tradicionales que almacenan los datos en filas, las bases de datos de columnas anchas organizan la información en columnas. Este enfoque permite un alto rendimiento en consultas que involucran grandes conjuntos de datos, ya que solo se acceden a las columnas relevantes para la consulta. Apache Cassandra es un ejemplo conocido de base de datos de columnas anchas. El almacenamiento por columnas resulta especialmente beneficioso para cargas de trabajo analíticas donde se necesita acceder a un subconjunto de columnas de una tabla muy grande.
Todo sobre Oracle Database: la base de datos líder en Colombia
El Enfoque en Objetos: Bases de Datos Orientadas a Objetos
Las bases de datos orientadas a objetos representan un paradigma donde la información se almacena en forma de objetos, de manera similar a como se estructuran los datos en la programación orientada a objetos. Este enfoque resulta particularmente adecuado para aplicaciones que manejan modelos de datos complejos, como sistemas multimedia o aplicaciones financieras, donde las entidades del mundo real pueden representarse de forma más natural como objetos con atributos y comportamientos asociados. La principal ventaja de este modelo radica en su capacidad para integrar directamente los datos con la lógica de programación orientada a objetos, lo que puede simplificar el desarrollo y mejorar la coherencia entre la aplicación y la base de datos. Understanding The Different Types Of Databases & When To Use Them
La integración de las bases de datos orientadas a objetos con los paradigmas de programación orientada a objetos puede simplificar significativamente el desarrollo de ciertas aplicaciones. En la programación orientada a objetos, los datos y las operaciones que se pueden realizar sobre ellos se combinan en unidades llamadas objetos. Las bases de datos orientadas a objetos permiten almacenar estos objetos directamente, sin necesidad de una traducción compleja a un modelo relacional basado en tablas. Esta correspondencia directa entre el modelo de datos de la base de datos y el modelo de objetos del lenguaje de programación puede reducir la cantidad de código necesario para acceder y manipular los datos, lo que a su vez puede acelerar el proceso de desarrollo y mejorar el mantenimiento de la aplicación.
La Jerarquía Estructurada: Bases de Datos Jerárquicas
Las bases de datos jerárquicas se caracterizan por organizar los datos siguiendo una estructura de árbol, donde se establecen relaciones de tipo padre-hijo. En este modelo, cada nodo hijo puede tener únicamente un nodo padre, aunque un nodo padre puede tener múltiples nodos hijos. Este tipo de organización fue una de las primeras formas de estructurar datos en bases de datos. Las bases de datos jerárquicas son especialmente eficientes y rápidas para acceder a datos que naturalmente se organizan en una jerarquía clara y bien definida, como la estructura de directorios y archivos en un sistema operativo o la representación de organigramas empresariales. Ejemplos concretos de sistemas que utilizan o han utilizado bases de datos jerárquicas incluyen sistemas de archivos y el Registro de Windows. What is a Hierarchical Database Systems?
Si bien las bases de datos jerárquicas han perdido terreno frente a otros modelos más flexibles para aplicaciones de propósito general, siguen siendo relevantes en sistemas donde la estructura de los datos es inherentemente jerárquica. La simplicidad de la relación uno a muchos entre padres e hijos puede ofrecer ventajas en términos de rendimiento para ciertas operaciones de consulta que siguen la jerarquía definida. Sin embargo, este modelo puede resultar menos adecuado para representar relaciones muchos a muchos complejas, lo que ha limitado su adopción en escenarios donde la interconexión de los datos es más intrincada.
Redes Complejas: Bases de Datos de Red
Las bases de datos de red representan una extensión del modelo jerárquico, permitiendo que cada registro se relacione con múltiples registros primarios y secundarios, formando así una estructura más compleja similar a un grafo. A diferencia del modelo jerárquico, donde cada hijo tiene un único padre, el modelo de red posibilita la existencia de múltiples padres e hijos para un mismo registro. Esta característica otorga una mayor flexibilidad para la representación de relaciones complejas entre los datos en comparación con el modelo jerárquico. Un ejemplo clásico de aplicación que históricamente ha utilizado bases de datos de red son los sistemas de reservas de aerolíneas, donde un vuelo puede tener múltiples pasajeros y un pasajero puede tener múltiples vuelos.
Aunque las bases de datos de red ofrecieron una mejora en la capacidad de modelado de relaciones complejas en comparación con el modelo jerárquico, su propia complejidad y la falta de un lenguaje de consulta estandarizado limitaron su adopción generalizada. Con el tiempo, los modelos relacionales y de grafos han surgido como alternativas más versátiles y fáciles de usar para la mayoría de las aplicaciones que requieren la representación de relaciones intrincadas entre los datos.
Otras Categorías:
Además de los tipos principales de bases de datos ya mencionados, existen otras categorías importantes que representan diferentes enfoques para el almacenamiento y la gestión de datos:
- Bases de datos distribuidas: En este modelo, los datos se almacenan en múltiples ubicaciones físicas, ya sea en diferentes computadoras dentro de una misma red o dispersas a través de redes geográficamente distantes.
- Almacenes de datos (Data Warehouses): Estos son repositorios centrales de datos diseñados específicamente para facilitar la realización de consultas y análisis rápidos sobre grandes volúmenes de información histórica.
- Bases de datos en memoria: A diferencia de las bases de datos tradicionales que almacenan la mayor parte de sus datos en discos duros, las bases de datos en memoria residen principalmente en la memoria interna (RAM) de la computadora, lo que permite un acceso a los datos mucho más rápido.
- Bases de datos en la nube: Estas bases de datos se ejecutan en plataformas de computación en la nube, ofreciendo beneficios como escalabilidad, flexibilidad y acceso desde cualquier lugar con conexión a internet.
- Bases de datos multimodel: Estos sistemas tienen la capacidad de combinar diferentes tipos de modelos de bases de datos (por ejemplo, relacional, documental, grafo) en una única plataforma integrada, lo que les permite manejar una variedad de tipos de datos.
- Bases de datos de series de tiempo: Están optimizadas para el almacenamiento y el análisis de datos que están indexados por una secuencia temporal, como lecturas de sensores o registros de eventos.
- Bases de datos vectoriales: Diseñadas específicamente para realizar búsquedas de similitud eficientes en datos de alta dimensión, como las representaciones vectoriales utilizadas en inteligencia artificial para el procesamiento de lenguaje natural o la visión por computadora.
- Bases de datos NewSQL: Buscan combinar la escalabilidad horizontal que ofrecen las bases de datos NoSQL con las propiedades ACID de las bases de datos relacionales tradicionales.
- Bases de datos auto-gestionadas (Autonomous Databases): Estas son bases de datos basadas en la nube que utilizan técnicas de aprendizaje automático para automatizar diversas tareas de gestión, como la optimización del rendimiento, la seguridad, las copias de seguridad y las actualizaciones.
- Bases de datos de código abierto: En este caso, el código fuente del sistema de gestión de la base de datos está disponible públicamente, lo que permite a los usuarios utilizarlo, modificarlo y distribuirlo libremente.
La existencia de esta amplia gama de tipos de bases de datos pone de manifiesto la diversidad de necesidades que existen en el ámbito del almacenamiento y el procesamiento de datos en el panorama tecnológico actual. Cada tipo de base de datos ha sido desarrollado y optimizado para abordar desafíos específicos o para mejorar el rendimiento en determinados casos de uso, lo que permite a las organizaciones seleccionar la solución que mejor se adapte a sus requerimientos particulares.
| Característica | Base de Datos Relacional (SQL) | Base de Datos NoSQL | Base de Datos Orientada a Objetos | Base de Datos Jerárquica | Base de Datos de Red |
| Modelo de Datos | Tablas con filas y columnas | Documentos, clave-valor, grafo, columnas | Objetos | Árbol (padre-hijo) | Grafo (múltiples padres e hijos) |
| Lenguaje de Consulta | SQL | Varios (depende del tipo) | Varios (depende del tipo) | Navegación | Navegación |
| Escalabilidad | Principalmente vertical | Horizontal | Depende de la implementación | Limitada | Limitada |
| Integridad de Datos | Alta (ACID) | Varía (puede ser eventual) | Depende de la implementación | Alta | Alta |
| Flexibilidad de Esquema | Baja | Alta | Media | Baja | Media |
| Casos de Uso Típicos | Sistemas transaccionales, CRM, e-commerce | Big data, tiempo real, IoT, redes sociales | Multimedia, sistemas financieros | Sistemas de archivos, jerarquías claras | Sistemas de reservas, relaciones complejas |
Aplicaciones en el Mundo Real: ¿Dónde se Utilizan las Bases de Datos?

En el Mundo Empresarial:
El uso de bases de datos es omnipresente en el mundo empresarial moderno, sustentando una amplia variedad de operaciones y funciones. En el ámbito del comercio electrónico, las bases de datos son esenciales para almacenar información detallada sobre productos, gestionar los datos de los usuarios, procesar los detalles de pago, mantener un registro del historial de transacciones y controlar el inventario. Los sistemas de gestión de relaciones con el cliente (CRM) dependen de bases de datos para organizar y rastrear la información sobre cuentas de clientes, contactos, clientes potenciales y oportunidades de venta. Para las empresas que manejan productos físicos, las bases de datos son cruciales para el seguimiento de inventario, indicando las cantidades disponibles en almacenes y estanterías, a menudo integrando tecnologías como códigos de barras y escáneres para una gestión eficiente.
La gestión financiera también se apoya fuertemente en las bases de datos para mantener registros precisos, garantizar el cumplimiento de las regulaciones y facilitar el análisis de la información económica. En el área de gestión de recursos humanos, las bases de datos simplifican procesos como la gestión de nóminas, la programación de horarios y el seguimiento de las revisiones de desempeño de los empleados. Los sistemas de reservas, utilizados en sectores como viajes, hotelería y otros servicios, emplean bases de datos para gestionar la disponibilidad de recursos y procesar las reservas de manera eficiente.
En un contexto de creciente preocupación por la seguridad y la prevención del fraude, las bases de datos de grafos han demostrado ser valiosas en la detección de fraude, ayudando en la gestión de identidades y la identificación de actividades sospechosas. La gestión de la cadena de suministro se beneficia del uso de bases de datos para realizar un seguimiento exhaustivo de los productos, desde los niveles de inventario hasta el estado de las entregas. El análisis de datos, una función cada vez más importante para la toma de decisiones empresariales, se basa en la capacidad de las bases de datos para almacenar grandes cantidades de información que luego pueden ser analizadas para identificar tendencias y patrones. Finalmente, las aplicaciones móviles y web utilizan bases de datos en su backend para almacenar datos de usuarios, preferencias y otra información esencial para su funcionamiento. 8 Top Database Management Systems (DBMS)
La presencia y la funcionalidad de las bases de datos son, por lo tanto, intrínsecas al funcionamiento de las empresas modernas. Su capacidad para organizar, almacenar y acceder a vastas cantidades de datos permite a las organizaciones operar de manera eficiente, realizar análisis profundos y tomar decisiones informadas en prácticamente todos los aspectos de sus negocios.
Fundamentos de Bases de Datos: Una Guía Completa
En el Ámbito Educativo:
Las bases de datos desempeñan un papel crucial en diversas funciones dentro del ámbito educativo. Los Sistemas de Información Estudiantil (SIS) son fundamentales para gestionar la información personal de los estudiantes, sus registros académicos, las inscripciones a cursos y los detalles financieros. Los Sistemas de Gestión del Aprendizaje (LMS) utilizan bases de datos para alojar contenido educativo en línea y realizar un seguimiento de la participación y el progreso de los estudiantes en los materiales de aprendizaje. Para la investigación y el acceso al conocimiento, las Bases de Datos de Investigación ofrecen una vasta colección de revistas académicas, artículos y otros recursos eruditos, como ProQuest, JSTOR, PubMed y ERIC. Types of Education Databases from K-12 to Higher Education
En la gestión del aula, los profesores pueden utilizar libros de calificaciones electrónicos basados en bases de datos para registrar las notas de los estudiantes en tareas, exámenes y otras evaluaciones. La planificación y organización del currículo se facilitan mediante las Bases de Datos de Currículo y Planificación de Lecciones, que ayudan a los educadores a crear y gestionar sus planes de enseñanza y recursos didácticos. La administración de la ayuda financiera y las becas se realiza de manera eficiente a través de Bases de Datos de Ayuda Financiera y Becas, que gestionan las solicitudes, los desembolsos y la información relacionada. Finalmente, las instituciones educativas también mantienen Bases de Datos de Antiguos Alumnos para mantener el contacto con sus graduados, almacenar información sobre su trayectoria profesional y gestionar las relaciones con la comunidad de exalumnos.
En resumen, las bases de datos son un componente esencial para la administración, la enseñanza y la investigación dentro de las instituciones educativas. Mejoran la eficiencia en la gestión de la información y facilitan el acceso a recursos valiosos tanto para el personal educativo como para los estudiantes.
En la Ciencia y la Investigación:
En el ámbito de la ciencia y la investigación, las bases de datos son herramientas indispensables para la organización, el acceso y el intercambio de datos. Las Bases de Datos Bibliográficas proporcionan registros detallados de artículos científicos, libros y otras publicaciones académicas, incluyendo información como el autor, el título, la revista o editorial y el tema. Ejemplos prominentes incluyen Scopus y Web of Science. Algunas bases de datos van más allá de la información bibliográfica y ofrecen Bases de Datos de Texto Completo, permitiendo a los investigadores acceder al contenido completo de las publicaciones. También existen Bases de Datos Numéricas que se centran en la recopilación y el almacenamiento de información cuantitativa, como estadísticas y datos demográficos. En el campo de la investigación, las Bases de Datos de Datos Científicos juegan un papel crucial al recopilar y organizar datos experimentales y observacionales en diversas disciplinas científicas, facilitando su análisis y reutilización por parte de la comunidad investigadora. Ejemplos de estas bases de datos incluyen Gene Expression Omnibus y Protein Data Bank. Además, algunas bases de datos se especializan en el almacenamiento de información multimedia, como Bases de Datos de Imágenes y Audio, que pueden ser relevantes en campos como la biología, la medicina o las artes.
La capacidad de las bases de datos para organizar, indexar y permitir la búsqueda eficiente de grandes cantidades de información es fundamental para el progreso científico. Facilitan la colaboración entre investigadores, permiten la verificación de resultados y fomentan el avance del conocimiento al hacer que los datos y la literatura científica sean accesibles a una amplia audiencia.
El Motor Interno: Sistemas de Gestión de Bases de Datos (SGBD)
Definición y Propósito:
Un Sistema de Gestión de Bases de Datos (SGBD) es un conjunto de software diseñado para permitir a los usuarios crear y administrar bases de datos. Actúa como una interfaz entre los usuarios y la base de datos, proporcionando las herramientas necesarias para crear, proteger, leer, actualizar y eliminar datos de manera eficiente. El SGBD es responsable de la gestión del almacenamiento físico de los datos, así como de su recuperación y manipulación. En esencia, otorga a los usuarios el control sobre la información almacenada, permitiéndoles organizar y acceder a los datos según sus necesidades específicas. Además de la gestión de los datos en sí, el SGBD también administra el motor que facilita el acceso a estos datos y define el esquema de la base de datos, es decir, su estructura organizativa. Una de las funciones primordiales del SGBD es garantizar la seguridad e integridad de los datos almacenados. What is Database Management & DBMS
El SGBD se erige como la capa de software fundamental que posibilita la interacción con las bases de datos, abstrayendo la complejidad inherente al almacenamiento y la gestión de grandes volúmenes de información. Sin un SGBD, la tarea de acceder y manipular los datos de manera eficiente y segura se volvería extremadamente ardua para los usuarios y las aplicaciones. El SGBD proporciona una interfaz estandarizada y un conjunto de herramientas que simplifican estas operaciones, permitiendo a los usuarios centrarse en la información en sí en lugar de en los detalles técnicos de su almacenamiento.
Funciones Clave de un SGBD:
Un SGBD desempeña una amplia gama de funciones esenciales para la gestión eficaz de las bases de datos. Entre ellas se encuentra la definición de datos, que implica la creación y modificación de la estructura de la base de datos, incluyendo la definición de tablas, campos y sus tipos de datos. La manipulación de datos es otra función crucial, que permite insertar nuevos registros, actualizar la información existente y eliminar datos cuando sea necesario. La capacidad de realizar consultas de datos, es decir, recuperar información específica de la base de datos basándose en ciertos criterios, es fundamental para el acceso a la información. What is a Database Management System (DBMS)? The Backbone of Modern Data Infrastructure
El control de acceso es vital para la seguridad de los datos, permitiendo al SGBD gestionar los permisos de usuario y garantizar que solo las personas autorizadas puedan acceder a la información sensible. La función de almacenamiento y recuperación de datos se encarga de la gestión física de cómo se guardan los datos en los dispositivos de almacenamiento y cómo se acceden a ellos cuando se solicitan. La integridad de datos es una preocupación primordial, y el SGBD implementa mecanismos para asegurar la precisión y la consistencia de la información almacenada, a menudo mediante la definición de reglas y restricciones. La seguridad de datos va más allá del control de acceso e incluye medidas para proteger la información contra accesos no autorizados, modificaciones o eliminaciones accidentales o malintencionadas.
Para garantizar la disponibilidad de la información incluso en caso de fallos del sistema o errores humanos, el SGBD proporciona funcionalidades de copia de seguridad y recuperación, permitiendo la restauración de los datos a un estado anterior. En entornos donde múltiples usuarios necesitan acceder y modificar la base de datos simultáneamente, el control de concurrencia es esencial para evitar conflictos y asegurar la integridad de los datos. Finalmente, la administración de transacciones garantiza que las operaciones que implican múltiples pasos se realicen de manera fiable, adhiriéndose a las propiedades ACID para asegurar la atomicidad, consistencia, aislamiento y durabilidad de las transacciones.
En conjunto, estas funciones del SGBD son cruciales para asegurar que las bases de datos sean sistemas confiables, seguros y eficientes para la gestión de la información. Cada función aborda un aspecto crítico del ciclo de vida de los datos, desde su definición y manipulación hasta su protección y recuperación.
Ejemplos Comunes de SGBD:
Existe una amplia variedad de Sistemas de Gestión de Bases de Datos disponibles, cada uno con sus propias características y optimizaciones para diferentes tipos de bases de datos y casos de uso. En el ámbito de las Bases de Datos Relacionales (RDBMS), algunos de los SGBD más populares incluyen Oracle Database, conocido por su robustez y amplias funcionalidades; MySQL, una opción de código abierto ampliamente utilizada en aplicaciones web; Microsoft SQL Server, una solución robusta para entornos empresariales, especialmente aquellos que utilizan tecnologías Microsoft; y PostgreSQL, otro RDBMS de código abierto reconocido por su extensibilidad y cumplimiento de estándares. Understanding The Different Types Of Databases & When To Use Them
Para las Bases de Datos NoSQL, se encuentran SGBD como MongoDB, una base de datos de documentos muy popular para aplicaciones web modernas; y Cassandra, una base de datos de columnas anchas diseñada para alta disponibilidad y escalabilidad.
Además de estos, existen otros SGBD relevantes como IBM Db2, un sistema de gestión de bases de datos relacionales de nivel empresarial; y SQLite, una base de datos ligera y autónoma, a menudo utilizada en aplicaciones móviles y de escritorio. Types of Databases
La diversidad de SGBD disponibles refleja la variedad de modelos de bases de datos existentes y las necesidades específicas de las diferentes aplicaciones. La elección del SGBD adecuado dependerá de factores como el tipo de datos que se van a gestionar, los requisitos de rendimiento, la necesidad de escalabilidad, el presupuesto disponible y la familiaridad del equipo de desarrollo con la tecnología.
Comunicándose con los Datos: Introducción a los Lenguajes de Consulta
El Propósito de los Lenguajes de Consulta:
Los lenguajes de consulta son lenguajes de programación especializados que se utilizan para interactuar con las bases de datos. Su propósito principal es permitir a los usuarios buscar información dentro de una base de datos o un conjunto de datos, modificar el contenido de la base de datos o recuperar información específica que cumpla con ciertos criterios. Estos lenguajes actúan como un puente de comunicación entre los usuarios o las aplicaciones y los datos almacenados, permitiendo especificar qué información se necesita y cómo debe ser manipulada. Efficient Database Management Systems for Small Schools
Los lenguajes de consulta son, por lo tanto, la interfaz principal a través de la cual los usuarios y las aplicaciones pueden acceder y modificar los datos almacenados en las bases de datos. Sin estos lenguajes, la información contenida en las bases de datos sería inaccesible y, por ende, de poca utilidad práctica. La capacidad de formular consultas precisas y eficientes es fundamental para extraer valor de los datos y para realizar tareas de gestión de la información de manera efectiva.
SQL: El Estándar para Bases de Datos Relacionales:
SQL (Structured Query Language) es, con diferencia, el lenguaje de consulta más ampliamente utilizado para la gestión de bases de datos relacionales. Este lenguaje permite a los usuarios realizar una amplia gama de operaciones, incluyendo la creación de nuevas bases de datos y tablas, la lectura o recuperación de datos existentes, la actualización de la información cuando sea necesario y la eliminación de datos que ya no se requieran. SQL es un lenguaje estandarizado, reconocido por organizaciones como ANSI (American National Standards Institute) e ISO (International Organization for Standardization), lo que garantiza un cierto nivel de compatibilidad entre diferentes sistemas de gestión de bases de datos relacionales. Query Languages: A Simple Introduction
La funcionalidad de SQL se articula a través de una serie de comandos, entre los que se destacan SELECT (para la recuperación de datos), INSERT (para la adición de nuevos registros), UPDATE (para la modificación de registros existentes) y DELETE (para la eliminación de registros). Estos comandos son fundamentales para realizar las operaciones básicas conocidas como CRUD (Create, Read, Update, Delete) en una base de datos. Además de estos comandos de manipulación de datos, SQL también incluye comandos para la definición de datos (DDL, Data Definition Language), que se utilizan para definir la estructura de la base de datos; comandos para el control de datos (DCL, Data Control Language), que gestionan los permisos de acceso a la base de datos; y comandos para el control de transacciones (TCL, Transaction Control Language), que aseguran la integridad de las operaciones que implican múltiples pasos. What are query languages?
La estandarización y la adopción generalizada de SQL lo han convertido en una habilidad esencial para cualquier persona que trabaje con bases de datos relacionales. La capacidad de escribir consultas SQL permite a los usuarios extraer información valiosa de las bases de datos, realizar análisis complejos y llevar a cabo tareas de gestión de datos de manera eficiente y precisa.
Lenguajes de Consulta NoSQL:
A diferencia del enfoque único de SQL para las bases de datos relacionales, las bases de datos NoSQL emplean lenguajes de consulta que están específicamente adaptados a sus modelos de datos particulares. Esto significa que no existe un lenguaje de consulta estándar universal para todas las bases de datos NoSQL, aunque algunos lenguajes han ganado popularidad dentro de ciertos tipos de bases de datos NoSQL. Por ejemplo, MQL (MongoDB Query Language) es el lenguaje de consulta utilizado principalmente con las bases de datos de documentos MongoDB, mientras que Cypher es un lenguaje de consulta diseñado específicamente para trabajar con bases de datos de grafos como Neo4j.
La diversidad de lenguajes de consulta en el mundo NoSQL refleja la variedad de modelos de datos que existen dentro de esta categoría de bases de datos. Cada lenguaje está optimizado para las operaciones y las estructuras de datos que son propias de su tipo de base de datos NoSQL. Si bien esto puede significar una curva de aprendizaje diferente para cada tipo de base de datos NoSQL, también permite una mayor eficiencia y expresividad en la interacción con los datos, ya que el lenguaje está diseñado para aprovechar al máximo las características del modelo de datos subyacente.
Otros Tipos de Lenguajes de Consulta:
Además de SQL y los lenguajes de consulta específicos de las bases de datos NoSQL, existen otros tipos de lenguajes de consulta que se utilizan en contextos particulares:
- GraphQL: Un lenguaje de consulta para APIs (Application Programming Interfaces) que permite a los clientes solicitar exactamente los datos que necesitan, optimizando la eficiencia en la recuperación de información.
- SPARQL: Un lenguaje de consulta y protocolo para interrogar datos RDF (Resource Description Framework), utilizado en el contexto de la web semántica y los datos enlazados.
- XQuery: Un lenguaje de consulta diseñado para trabajar con colecciones de datos XML (Extensible Markup Language), ofreciendo potentes capacidades de manipulación y transformación de datos XML.
- DMX (Data Mining Extensions): Un lenguaje de consulta para modelos de minería de datos en SQL Server Analysis Services (SSAS), utilizado para la creación y gestión de modelos predictivos.
- MDX (Multidimensional Expressions): Un lenguaje de consulta para bases de datos OLAP (Online Analytical Processing), diseñado para realizar consultas complejas sobre datos multidimensionales, como los utilizados en data warehousing y business intelligence.
- Datalog: Un lenguaje de consulta declarativo basado en la programación lógica, utilizado en bases de datos deductivas y en aplicaciones de representación del conocimiento.
- Lenguajes de consulta de texto completo: Especializados en la búsqueda de texto no estructurado dentro de las bases de datos, ofreciendo capacidades avanzadas de búsqueda como la coincidencia de patrones y el ranking de texto.
- Lenguajes de consulta de lenguaje natural: Intentan hacer que la interacción con las bases de datos sea más accesible para usuarios no técnicos, permitiendo realizar consultas utilizando expresiones en lenguaje humano en lugar de sintaxis de consulta formal. Database Trends: A 2024 Review and a Look Ahead
La existencia de estos lenguajes de consulta especializados subraya la necesidad de herramientas que estén adaptadas a diferentes tipos de datos y a tareas específicas de procesamiento de información. Si bien SQL sigue siendo dominante en el ámbito de las bases de datos relacionales, otros lenguajes ofrecen funcionalidades optimizadas para casos de uso particulares, lo que demuestra la continua evolución y especialización en el campo de la gestión de datos.
Ejemplos Prácticos: Consultas SQL Básicas en Acción
SELECT: Recuperando Datos
La instrucción SELECT es la piedra angular de SQL, utilizada para recuperar datos de una o más tablas en una base de datos. Una de sus formas más básicas permite ver todos los registros y todas las columnas de una tabla. Por ejemplo, la consulta SELECT * FROM Employee; devolvería todas las filas y todas las columnas de la tabla denominada “Employee”.
Sin embargo, a menudo es necesario seleccionar solo columnas específicas de una tabla. Esto se logra listando los nombres de las columnas deseadas después de la palabra clave SELECT, separados por comas. Por ejemplo, para obtener solo los identificadores de empleado, los nombres y las edades de la tabla “Employee”, se utilizaría la consulta SELECT EMP_ID, NAME, AGE FROM Employee;.
La cláusula WHERE añade la capacidad de filtrar los resultados de una consulta basándose en una o más condiciones. Por ejemplo, si se quisiera obtener solo los empleados cuya edad sea mayor de 30 años, se podría escribir la consulta SELECT * FROM Employee WHERE AGE > 30;.
Además de seleccionar todas las filas que cumplen un criterio, a veces es útil obtener solo los valores únicos de una columna. La instrucción SELECT DISTINCT se utiliza para este propósito. Por ejemplo, SELECT DISTINCT DEPARTMENT FROM Employee; devolvería una lista de todos los departamentos diferentes que aparecen en la tabla “Employee”, sin duplicados. 15 Most Common SQL Queries with Examples
El orden en que se presentan los resultados de una consulta también puede ser importante. La cláusula ORDER BY permite especificar una o más columnas por las cuales se deben ordenar los resultados, ya sea en orden ascendente (ASC, por defecto) o descendente (DESC). Por ejemplo, para ver todos los empleados ordenados por edad de mayor a menor, se usaría la consulta SELECT * FROM Employee ORDER BY AGE DESC;.
Finalmente, en algunas ocasiones, solo se necesita un número limitado de filas de los resultados de una consulta. La cláusula LIMIT permite especificar el número máximo de filas que se deben devolver. Por ejemplo, SELECT * FROM Employee LIMIT 10; devolvería las primeras 10 filas de la tabla “Employee”.
La versatilidad de la consulta SELECT la convierte en la operación más fundamental en SQL, ya que permite a los usuarios extraer precisamente la información que necesitan de las bases de datos para su análisis y toma de decisiones.
INSERT: Agregando Nuevos Registros
La instrucción INSERT INTO se utiliza para añadir nuevas filas o registros a una tabla existente en la base de datos. Para especificar en qué tabla se va a insertar el nuevo registro y qué valores se van a asignar a cada columna, se utiliza la siguiente sintaxis: INSERT INTO table_name (column1, column2, column3,…) VALUES (value1, value2, value3,…);. Por ejemplo, para agregar un nuevo empleado a la tabla “Employee” con un ID de 4, nombre “Charlie”, salario de 40000 y edad de 36, se podría utilizar la siguiente instrucción: INSERT INTO Employee (EMP_ID, NAME, SALARY, AGE) VALUES (4, ‘Charlie’, 40000, 36);. Es importante que los valores proporcionados en la cláusula VALUES correspondan en orden y tipo de datos a las columnas especificadas en la cláusula de columnas (si se omite la lista de columnas, se deben proporcionar valores para todas las columnas de la tabla en su orden definido). La capacidad de insertar nuevos datos es fundamental para mantener las bases de datos actualizadas y reflejar la información más reciente.
UPDATE: Modificando Registros Existentes
La instrucción UPDATE se emplea para modificar los valores de una o más columnas en los registros existentes de una tabla. La sintaxis básica de esta instrucción es: UPDATE table_name SET column1 = value1, column2 = value2,… WHERE condition;. La cláusula SET especifica qué columnas se van a actualizar y con qué nuevos valores, mientras que la cláusula WHERE (opcional, pero muy recomendable) define qué registros se van a modificar. Si se omite la cláusula WHERE, se actualizarán todas las filas de la tabla. Por ejemplo, si se quisiera aumentar el salario del empleado con ID 4 a 45000, se podría utilizar la siguiente consulta: UPDATE Employee SET SALARY = 45000 WHERE EMP_ID = 4;. La instrucción UPDATE es esencial para mantener la precisión de los datos en la base de datos, permitiendo corregir errores, reflejar cambios en la información y mantener los registros actualizados.
DELETE: Eliminando Registros
La instrucción DELETE FROM se utiliza para eliminar filas específicas de una tabla en la base de datos. La sintaxis básica es: DELETE FROM table_name WHERE condition;. Al igual que con la instrucción UPDATE, la cláusula WHERE es crucial para especificar qué filas se van a eliminar. Si se omite la cláusula WHERE, se eliminarán todas las filas de la tabla, lo cual es una operación irreversible y debe realizarse con precaución. Por ejemplo, para eliminar el registro del empleado con ID 4 de la tabla “Employee”, se utilizaría la siguiente consulta: DELETE FROM Employee WHERE EMP_ID = 4;. La capacidad de eliminar datos es importante para mantener la base de datos libre de información obsoleta, incorrecta o innecesaria, asegurando que solo contenga datos relevantes y precisos.
CREATE TABLE: Definiendo la Estructura
La instrucción CREATE TABLE se utiliza para crear una nueva tabla dentro de la base de datos. Al crear una tabla, se debe especificar su nombre y definir las columnas que contendrá, incluyendo el nombre de cada columna y su tipo de datos. La sintaxis general es: CREATE TABLE table_name (column1 datatype, column2 datatype, column3 datatype,…);. Por ejemplo, para crear una tabla llamada “Department” con dos columnas, “DEPT_ID” de tipo entero y “DEPT_NAME” de tipo texto (varchar de 255 caracteres), se podría utilizar la siguiente instrucción: CREATE TABLE Department (DEPT_ID int, DEPT_NAME varchar(255));. La instrucción CREATE TABLE es fundamental para definir el esquema y la estructura lógica de una base de datos antes de que se puedan almacenar datos en ella.
ALTER TABLE: Modificando la Estructura
Una vez que una tabla ha sido creada, puede ser necesario modificar su estructura. La instrucción ALTER TABLE se utiliza para realizar cambios en la definición de una tabla existente, como agregar nuevas columnas, eliminar columnas existentes o modificar las propiedades de las columnas (por ejemplo, su tipo de datos). Por ejemplo, para agregar una nueva columna llamada “EMAIL” de tipo texto (varchar de 255 caracteres) a la tabla “Employee”, se podría utilizar la siguiente instrucción: ALTER TABLE Employee ADD COLUMN EMAIL varchar(255);. La instrucción ALTER TABLE proporciona la flexibilidad necesaria para adaptar la estructura de la base de datos a medida que evolucionan los requisitos de la aplicación o del negocio.
DROP TABLE: Eliminando Tablas
Finalmente, la instrucción DROP TABLE se utiliza para eliminar una tabla completa de la base de datos, junto con todos los datos que contiene. La sintaxis es muy simple: DROP TABLE table_name;. Por ejemplo, para eliminar la tabla “Department” creada anteriormente, se utilizaría la instrucción DROP TABLE Department;. Es importante tener precaución al utilizar esta instrucción, ya que la eliminación de una tabla es una operación permanente y todos los datos contenidos en ella se perderán. La instrucción DROP TABLE es útil para eliminar tablas que ya no son necesarias, ayudando a mantener la base de datos organizada y a liberar espacio de almacenamiento.
La Columna Vertebral de la Información: Importancia de las Bases de Datos
Organización y Gestión Eficiente de Datos:
Las bases de datos ofrecen una estructura sistemática para almacenar y organizar datos de manera eficiente, lo que facilita su gestión y acceso. Al proporcionar un marco coherente para la organización de la información, las bases de datos no solo mantienen la integridad de los datos, sino que también eliminan las duplicaciones y reducen la aparición de inconsistencias. Un Sistema de Gestión de Bases de Datos (SGBD) actúa como una conexión entre las aplicaciones y las bases de datos, asegurando que los datos se organicen y se puedan acceder de manera consistente. Permite el acceso y la gestión de los datos, y define la estructura misma de la base de datos. 10 Importance & Benefits of Database Management System
La organización estructurada que ofrecen las bases de datos es fundamental para la eficacia en la recuperación y el análisis de la información. Un sistema de almacenamiento bien organizado permite a los usuarios implementar consultas complejas para ordenar, filtrar y analizar grandes conjuntos de datos, lo que a su vez mejora la eficiencia y minimiza los tiempos de respuesta. Esta capacidad de gestión eficiente es esencial para mantener la integridad de los datos y garantizar que la información sea precisa y consistente.
Recuperación Rápida y Eficaz de Información:
Una de las ventajas clave de las bases de datos es su capacidad para recuperar información de manera rápida y eficaz. Pueden ejecutar consultas complejas sobre extensos conjuntos de datos en cuestión de segundos, proporcionando una eficiencia notable en la recuperación de información. Esta capacidad resulta indispensable para la gestión y la obtención de información valiosa a partir de grandes volúmenes de datos. Los SGBD permiten realizar consultas complejas utilizando lenguajes como SQL, lo que facilita la búsqueda y el filtrado de la información necesaria para la toma de decisiones oportuna.
En entornos empresariales y científicos, la velocidad con la que se puede acceder a la información puede marcar una diferencia significativa. Las bases de datos están diseñadas para optimizar este proceso, utilizando técnicas de indexación y almacenamiento eficiente para asegurar que las consultas se ejecuten de la manera más rápida posible.
Integridad y Precisión de los Datos:
Las bases de datos aseguran la precisión y la consistencia de los datos a través de un diseño cuidadoso y la definición de restricciones bien definidas. Mediante la imposición de reglas y restricciones, como el uso de claves primarias y foráneas, se ayuda a evitar irregularidades como la introducción de datos inválidos o la duplicación de registros. Esta consistencia es vital, especialmente cuando múltiples usuarios acceden y modifican los datos de manera concurrente. Un SGBD confirma que los datos se mantienen consistentes y precisos, lo cual es fundamental para la confiabilidad de la información almacenada.
Seguridad y Protección de Datos:
La seguridad de los datos es una preocupación primordial en el mundo digital actual, y las bases de datos ofrecen funcionalidades esenciales para proteger la información sensible. Esto incluye la implementación de mecanismos de autenticación de usuarios, la definición de mecanismos de autorización para controlar el acceso a los datos y el uso de protocolos de cifrado para proteger la confidencialidad de la información. Un SGBD ofrece sólidas características de seguridad, permitiendo a los administradores de datos definir quién puede acceder, modificar o eliminar la información, y también proporciona registros de auditoría para monitorizar la actividad de los usuarios. Las bases de datos implementan medidas de seguridad para proteger los datos del acceso, la modificación o la eliminación no autorizados, incluyendo la autenticación y autorización de usuarios, el cifrado de datos sensibles y mecanismos de auditoría para rastrear los cambios realizados en la base de datos. What is Database Management & DBMS
Escalabilidad y Adaptabilidad:
A medida que las empresas crecen y la cantidad de datos que manejan aumenta, es esencial que sus sistemas de gestión de datos puedan escalar de manera eficiente. Un SGBD está diseñado para escalar, acomodando un número creciente de datos y usuarios sin comprometer el rendimiento. Esto incluye la capacidad de manejar grandes volúmenes de datos a medida que el negocio se expande. La escalabilidad garantiza que la base de datos pueda gestionar grandes cargas de trabajo, un mayor número de usuarios concurrentes y consultas complejas. Esto se logra tanto a través de la escalabilidad vertical (aumentando la capacidad de los servidores existentes) como de la escalabilidad horizontal (añadiendo más servidores al sistema).
Copia de Seguridad y Recuperación ante Desastres:
La posibilidad de pérdida de datos debido a fallos del sistema, errores humanos o desastres naturales es una amenaza para cualquier organización. Por ello, los SGBD vienen equipados con mecanismos integrados de copia de seguridad y recuperación para garantizar la protección contra la pérdida de información crítica. Estos mecanismos permiten realizar copias de seguridad de los datos a intervalos regulares y restaurarlos en caso de pérdidas accidentales o fallas del sistema. Esto asegura la continuidad del negocio y minimiza el tiempo de inactividad en caso de eventos inesperados.
Compartición de Datos Optimizada:
En muchas organizaciones, la información se genera y utiliza en diferentes departamentos. Un SGBD simplifica el intercambio de datos entre estas diversas áreas, permitiendo un acceso más fluido a la información. Facilita entornos multiusuario donde muchos individuos pueden acceder a los mismos datos simultáneamente sin conflictos. El SGBD gestiona las transacciones de manera que múltiples usuarios pueden trabajar juntos en datos compartidos sin comprometer la integridad de la información.
Mejora del Rendimiento:
Un SGBD está diseñado para optimizar el uso de los recursos del sistema y minimizar el tiempo requerido para implementar consultas e informes complejos. Esto se logra a través de diversas técnicas, como la indexación de datos, la optimización de consultas y el almacenamiento eficiente de la información. Un buen SGBD permite mejorar el rendimiento de las consultas, reduciendo los tiempos de respuesta y facilitando el análisis de grandes conjuntos de datos.
Cumplimiento Normativo:
En un entorno regulatorio cada vez más estricto, el cumplimiento de las normativas de protección de datos es crucial para las empresas que manejan información sensible. Un SGBD ayuda a las organizaciones a cumplir con estas regulaciones al mantener datos precisos y ofrecer registros de auditoría detallados sobre el acceso y las modificaciones realizadas a la información. Esto permite rastrear las modificaciones y el acceso a los datos, y también soporta políticas de retención de datos, garantizando que la información se almacene de forma segura y de acuerdo con los estándares de la industria. Al ayudar a las empresas a cumplir con las demandas regulatorias, un SGBD reduce el riesgo de sanciones legales y mejora la reputación de la organización.
Impulsando Decisiones Inteligentes: El Papel de las Bases de Datos en la Toma de Decisiones
Análisis de Datos y Obtención de Información:
Las bases de datos permiten a las organizaciones analizar sus datos de manera efectiva, lo que a su vez conduce a una toma de decisiones más informada y estratégica. Son fundamentales en la generación de informes detallados, la elaboración de pronósticos precisos y la identificación de tendencias clave que son esenciales para la planificación estratégica a largo plazo. Al almacenar grandes cantidades de datos históricos y en tiempo real, las bases de datos proporcionan la materia prima necesaria para identificar patrones, tendencias y correlaciones que pueden no ser evidentes a simple vista. Esta capacidad de análisis profundo permite a las empresas comprender mejor su rendimiento actual, anticipar futuros desafíos y oportunidades, y tomar decisiones basadas en evidencia sólida en lugar de intuiciones o suposiciones.
Identificación de Oportunidades y Tendencias:
El análisis de los datos almacenados en las bases de datos puede revelar nuevas oportunidades de negocio y tendencias emergentes en el mercado que de otra manera podrían pasar desapercibidas. Al examinar los patrones de compra de los clientes, las preferencias del mercado, el rendimiento de los productos y otros datos relevantes, las organizaciones pueden identificar segmentos de mercado sin explotar, predecir cambios en la demanda y adaptar sus estrategias en consecuencia. Las bases de datos permiten a las empresas ir más allá de las hojas de cálculo estáticas, descubriendo información valiosa que puede impulsar la innovación, la expansión a nuevos mercados y la mejora de la oferta de productos y servicios. Esta capacidad de anticipar tendencias y aprovechar nuevas oportunidades es crucial para mantener la competitividad en un entorno empresarial dinámico.
Mejora de la Eficiencia y la Productividad:
Las bases de datos pueden automatizar una serie de tareas rutinarias relacionadas con la gestión de la información, como la entrada de datos, la actualización de registros y la generación de informes periódicos. Esta automatización libera recursos humanos y reduce la posibilidad de errores manuales, lo que conduce a una mejora general de la eficiencia y la productividad. Al facilitar el acceso rápido y preciso a la información, las bases de datos permiten a los empleados realizar sus tareas de manera más eficiente y tomar decisiones más rápidas y fundamentadas. Además, la capacidad de integrar las bases de datos con otras aplicaciones empresariales puede optimizar aún más los flujos de trabajo y mejorar la colaboración entre diferentes departamentos.
Personalización y Mejora de la Experiencia del Cliente:
El análisis detallado de los datos de los clientes almacenados en las bases de datos permite a las organizaciones ofrecer experiencias más personalizadas y campañas de marketing más dirigidas. Al comprender las preferencias, el historial de compras, los datos demográficos y otros detalles relevantes de sus clientes, las empresas pueden adaptar sus productos, servicios y mensajes de marketing a las necesidades específicas de cada individuo o segmento de mercado. Esta personalización no solo mejora la satisfacción del cliente y fomenta la lealtad a la marca, sino que también puede aumentar la efectividad de las campañas de marketing y las ventas. 7 ways a good database can improve your business
Predicción y Planificación:
Las bases de datos proporcionan la base para utilizar técnicas de análisis predictivo, que permiten a las organizaciones anticipar tendencias futuras, identificar posibles desafíos y tomar medidas preventivas de manera proactiva. Al analizar datos históricos y actuales, las empresas pueden desarrollar modelos predictivos que les ayuden a pronosticar la demanda, optimizar la gestión de inventario, predecir el comportamiento del cliente y tomar decisiones estratégicas más informadas. Esta capacidad de anticipación y planificación basada en datos es esencial para el éxito a largo plazo de las organizaciones, permitiéndoles adaptarse a los cambios del mercado, mitigar riesgos y aprovechar nuevas oportunidades.
El Panorama Actual: Tendencias Emergentes en el Mundo de las Bases de Datos
Bases de Datos en la Nube:
Una de las tendencias más significativas en el ámbito de las bases de datos es la creciente migración hacia la nube, impulsada por la escalabilidad, la rentabilidad y la accesibilidad que ofrece este modelo. Los modelos de base de datos como servicio (DBaaS) están ganando popularidad, ya que simplifican la gestión de las bases de datos al delegar tareas como el aprovisionamiento, el parcheado y la copia de seguridad a los proveedores de la nube. Además, se observa un creciente soporte para implementaciones híbridas y multi-nube, lo que permite a las organizaciones tener más flexibilidad en la elección de dónde almacenar y procesar sus datos. La adopción de bases de datos en la nube continúa su expansión, ofreciendo a las empresas la agilidad y la eficiencia necesarias en el entorno digital actual.
Adopción y Evolución de NoSQL:
Las bases de datos NoSQL siguen siendo una opción clave para las aplicaciones modernas que necesitan manejar grandes volúmenes de datos no estructurados y semiestructurados. Se observa una tendencia hacia el soporte multimodel en las bases de datos NoSQL, lo que les permite manejar diferentes tipos de datos dentro de la misma plataforma. La flexibilidad y la escalabilidad que ofrecen las bases de datos NoSQL las mantienen como una tecnología fundamental para el desarrollo de aplicaciones web y móviles de alto rendimiento.
Bases de Datos en Memoria:
Para aplicaciones que requieren tiempos de respuesta extremadamente rápidos, las bases de datos en memoria están ganando terreno.4 Al almacenar los datos principalmente en la memoria RAM en lugar de en discos, ofrecen un rendimiento superior en industrias como los juegos en línea, la banca y los sistemas de reservas de viajes, donde la latencia debe ser mínima.
Bases de Datos de Grafos:
A medida que las organizaciones lidian con datos cada vez más complejos e interconectados, las bases de datos de grafos están adquiriendo una importancia creciente. Su capacidad para representar y consultar eficientemente las relaciones entre puntos de datos las hace ideales para aplicaciones como redes sociales, sistemas de recomendación, detección de fraude y gestión de cadenas de suministro.
Bases de Datos Auto-gestionadas (Autonomous Databases):
La aparición de bases de datos auto-gestionadas, que utilizan inteligencia artificial y aprendizaje automático para automatizar tareas de gestión rutinarias como la optimización, las copias de seguridad y los parches, promete reducir la carga administrativa y mejorar la eficiencia operativa. El objetivo es minimizar los errores humanos y reducir el tiempo de inactividad, permitiendo a los administradores de bases de datos centrarse en tareas más estratégicas.
Integración de Inteligencia Artificial (IA) y Aprendizaje Automático (ML):
La integración de la inteligencia artificial y el aprendizaje automático está transformando la forma en que se gestionan y se utilizan las bases de datos. Esto incluye el uso de IA y ML para el análisis de datos mejorado, la detección de anomalías y la automatización de tareas de gestión. Las bases de datos vectoriales, diseñadas para búsquedas de similitud eficientes en datos de alta dimensión, son esenciales para muchas aplicaciones de IA, como el procesamiento de lenguaje natural y la visión por computadora. También se están desarrollando interfaces de lenguaje natural a SQL, lo que facilitará la interacción con las bases de datos para usuarios no técnicos.
Bases de Datos Serverless:
El modelo serverless está ganando tracción en el ámbito de las bases de datos, donde los proveedores de la nube gestionan la infraestructura subyacente, lo que simplifica la implementación y la escalabilidad para los desarrolladores. Los usuarios pagan solo por los recursos que consumen, lo que puede resultar más rentable para ciertas cargas de trabajo. The future of database management in an AI-driven world
Data Fabric y Data Mesh:
Para gestionar la creciente complejidad de los entornos de datos distribuidos, están surgiendo enfoques como Data Fabric y Data Mesh. Data Fabric busca conectar y federar diferentes fuentes de datos a través de metadatos, mientras que Data Mesh promueve un enfoque descentralizado para la gestión de datos, donde los equipos responsables de los datos también son responsables de su gestión y calidad.
Data Observability:
Finalmente, Data Observability se está convirtiendo en una tendencia importante para garantizar la confiabilidad y la precisión de los datos en los sistemas de bases de datos. Se centra en la comprensión de la calidad de los datos y el monitoreo de la salud de los datos, ayudando a las organizaciones a identificar y resolver problemas de calidad de datos de manera proactiva.
El Presente y Futuro de la Gestión de Datos
En este informe, se ha explorado en detalle qué es una base de datos y cómo se utiliza en una variedad de contextos. Desde su definición más sencilla como una herramienta para organizar información hasta su papel fundamental en las complejas operaciones empresariales, la educación y la investigación científica, las bases de datos se han establecido como la columna vertebral de la gestión de la información en el mundo digital actual. Se han examinado los componentes fundamentales que conforman una base de datos, la diversidad de tipos que existen para satisfacer diferentes necesidades, el papel crucial de los Sistemas de Gestión de Bases de Datos (SGBD) en su administración y los lenguajes de consulta que permiten la interacción con los datos, con un enfoque particular en SQL.
La importancia de las bases de datos en la gestión eficiente de la información, la toma de decisiones inteligentes, la mejora de la eficiencia operativa y la garantía de la seguridad y el cumplimiento normativo ha quedado clara. Además, se han destacado las tendencias emergentes en el campo de las bases de datos, como la adopción de la nube, la evolución de NoSQL, el auge de las bases de datos de grafos y auto-gestionadas, la integración de la inteligencia artificial y el aprendizaje automático, y la aparición de conceptos como Data Fabric y Data Mesh.
En un mundo cada vez más impulsado por los datos, la capacidad de almacenar, organizar, gestionar y analizar información de manera efectiva es fundamental para el éxito de cualquier organización. Las bases de datos, en sus diversas formas y con sus continuas innovaciones, seguirán desempeñando un papel indispensable en este panorama, evolucionando para hacer frente a los desafíos y aprovechar las oportunidades que presenta el futuro de la gestión de datos.
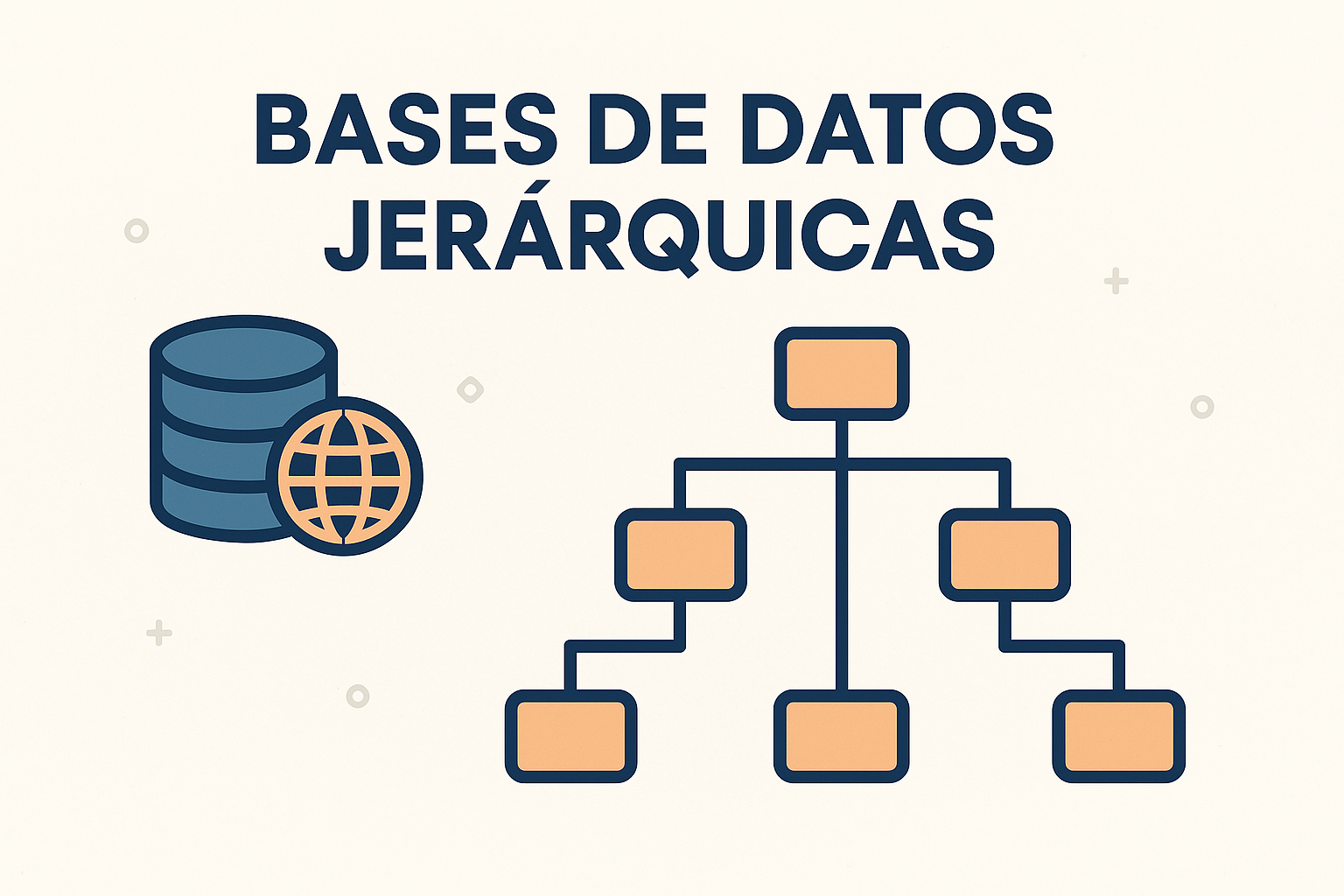
Bases de Datos Jerárquicas: la Estructura Troncal de la Información
En un mundo impulsado por datos, comprender cómo se organizan y gestionan es fundamental. Desde…

Poderosas Bases de Datos en Excel: Domina la Toma de Decisiones Estratégicas
¿Te ha pasado que abres una hoja de cálculo de Excel y te encuentras con…

Dominando las Bases de Datos de Ventas en Excel: Avanzando a Decisiones Estratégicas
Laura, gerente de ventas de una pequeña empresa de distribución de productos orgánicos en Bucaramanga,…

Tipos de Bases de Datos: una Elección entre Equilibrio, Funcionalidad, Rendimiento, Costo y Gestión
En la era digital actual, donde cada interacción, cada transacción y cada byte de información…

Bases de Datos XML: ¿Habilitadas o Nativas? Desentrañando el Almacenamiento y Gestión de Datos Jerárquicos en la Era Digital
En el vasto universo del Big Data y la analítica de datos, la elección de…
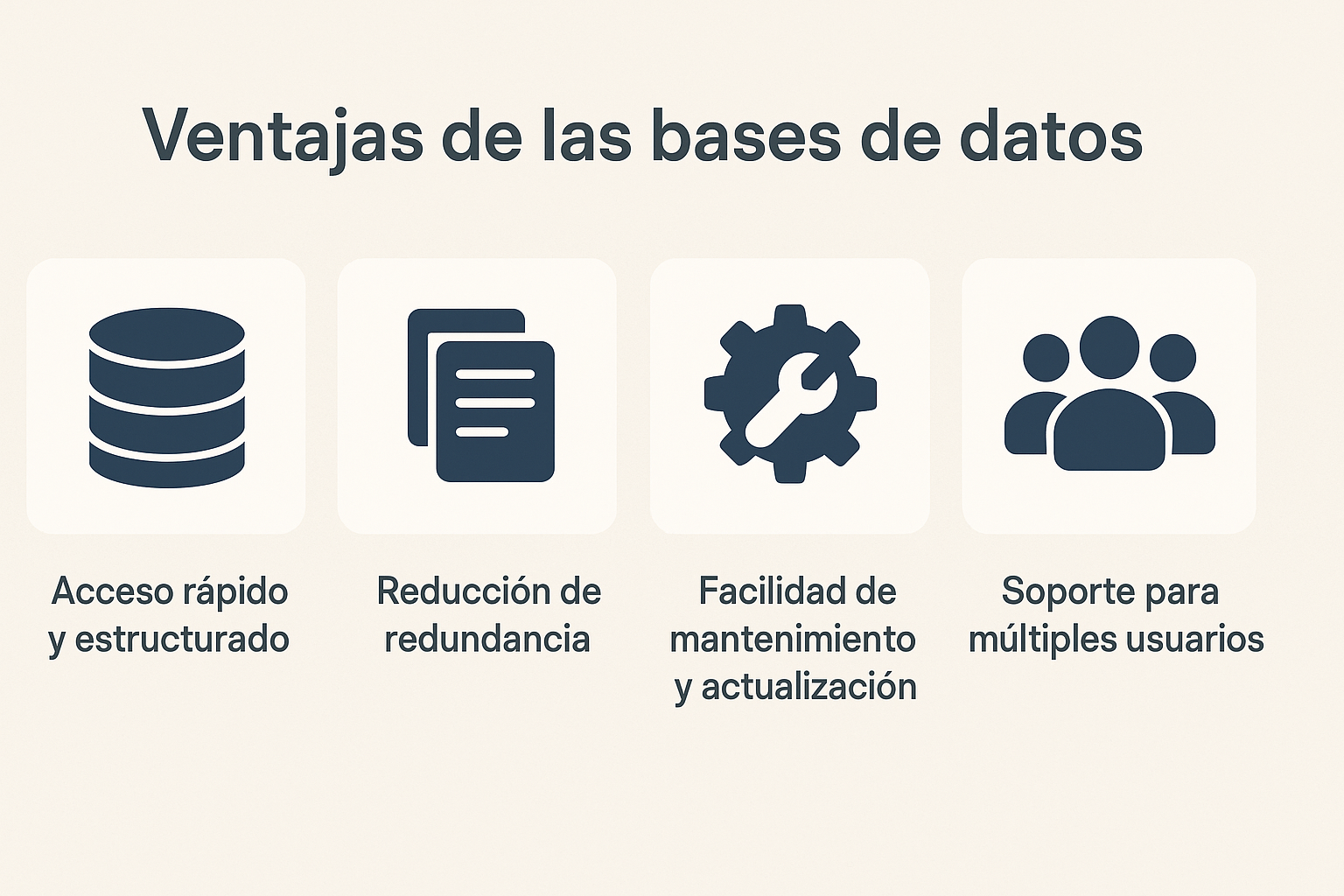
Bases de Datos: La Columna Vertebral de la Era Digital y sus Ventajas Innegables para 2025
En un mundo donde la información es el nuevo oro, la capacidad de recolectar, almacenar,…